「引言」 "成為SQL大師的秘訣在這里!🏆
把SQL(Structured Query Language,結(jié)構(gòu)化查詢語(yǔ)言)想象成數(shù)據(jù)世界的瑞士軍刀。在這個(gè)由數(shù)據(jù)構(gòu)建的宇宙里,沒(méi)有什么是一點(diǎn)SQL魔法解決不了的。
隨著數(shù)據(jù)量的增長(zhǎng),像偵探一樣尋找線索的數(shù)據(jù)專(zhuān)家越來(lái)越受歡迎。僅僅了解高級(jí)SQL概念可不夠哦,你得像魔法師一樣在工作中嫻熟地施展它們。面試時(shí),這可是贏得數(shù)據(jù)科學(xué)職位的法寶!
因此,我在這里列出了5個(gè)高級(jí)SQL概念,每個(gè)概念都配有解釋和查詢示例,助你在2022年成為數(shù)據(jù)界的魔法大師。
我特意將這篇文章保持簡(jiǎn)短,讓你能快速閱讀完畢,掌握這些必知的、讓面試官眼前一亮的SQL技巧。🏆
目錄
公共表表達(dá)式(Common Table Expressions, CTEs) 排序函數(shù):ROW_NUMBER() vs RANK() vs DENSE_RANK() 根據(jù)日期-時(shí)間列提取數(shù)據(jù) 📍示例數(shù)據(jù):使用Faker創(chuàng)建的虛擬銷(xiāo)售數(shù)據(jù),文末獲取。
. . .
公共表表達(dá)式(Common Table Expressions, CTEs) 在處理現(xiàn)實(shí)世界數(shù)據(jù)時(shí),有時(shí)你需要查詢另一個(gè)查詢的結(jié)果。一種簡(jiǎn)單的實(shí)現(xiàn)方法是使用子查詢。
然而,隨著復(fù)雜性的增加,計(jì)算子查詢變得難以閱讀和調(diào)試。
這時(shí),公共表表達(dá)式 (CTEs)就派上用場(chǎng),讓你的工作變得更加輕松。CTEs 使復(fù)雜查詢的編寫(xiě)和維護(hù)變得更簡(jiǎn)單。✅
例如,考慮使用以下子查詢進(jìn)行數(shù)據(jù)提取:
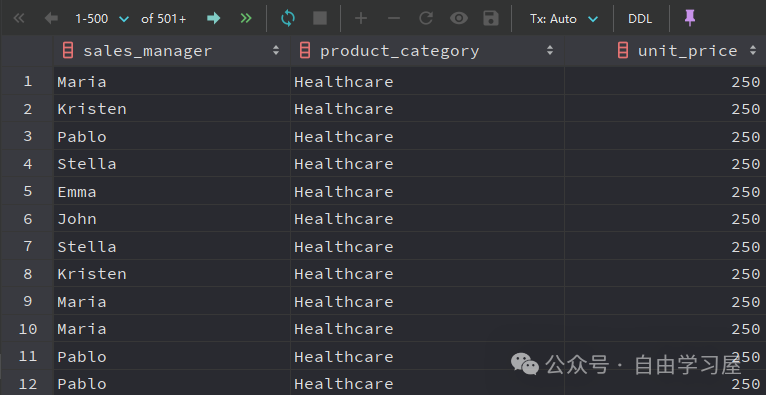
SELECT sales_manager, product_category, unit_priceFROM dummy_sales_dataWHERE sales_manager IN (SELECT DISTINCT sales_managerFROM dummy_sales_dataWHERE shipping_address = 'Germany' AND unit_price > 150 )AND product_category IN (SELECT DISTINCT product_categoryFROM dummy_sales_dataWHERE product_category = 'Healthcare' AND unit_price > 150 )ORDER BY unit_price DESC ;在這里,我僅使用了兩個(gè)易于理解的子查詢。
即使如此,要跟蹤這些查詢?nèi)匀缓芾щy,更不用說(shuō)當(dāng)你在子查詢中增加更多計(jì)算,或者甚至添加更多子查詢時(shí) —— 復(fù)雜性增加,使得代碼的可讀性和維護(hù)難度隨之增加。
現(xiàn)在,讓我們看看使用公共表表達(dá)式將上述子查詢簡(jiǎn)化后的版本,如下所示:
WITH SM AS SELECT DISTINCT sales_managerFROM dummy_sales_dataWHERE shipping_address = 'Germany' AND unit_price > 150 ),AS SELECT DISTINCT product_categoryFROM dummy_sales_dataWHERE product_category = 'Healthcare' AND unit_price > 150 )SELECT sales_manager, product_category, unit_priceFROM dummy_sales_dataWHERE sales_manager IN (SELECT sales_manager FROM SM)AND product_category IN (SELECT product_category FROM PC)ORDER BY unit_price DESC ;復(fù)雜的子查詢被分解為更簡(jiǎn)單的代碼塊。
通過(guò)這種方式,復(fù)雜的子查詢被重寫(xiě)為兩個(gè)更容易理解和修改的公共表表達(dá)式(CTE)SM 和PC 。🎯
以上兩個(gè)查詢執(zhí)行時(shí)間相同,結(jié)果如下所示:
公共表表達(dá)式 (CTE)本質(zhì)上允許您根據(jù)查詢結(jié)果創(chuàng)建一個(gè)臨時(shí)表。這提高了代碼的可讀性和維護(hù)性。✅
現(xiàn)實(shí)世界的數(shù)據(jù)集可能有數(shù)百萬(wàn)或數(shù)十億行,占用數(shù)千GB的存儲(chǔ)空間。直接使用這些表中的數(shù)據(jù)進(jìn)行計(jì)算,尤其是將它們與其他表連接起來(lái),將是非常昂貴的。
對(duì)于此類(lèi)任務(wù)的最佳解決方案是使用CTE。💯
接下來(lái),讓我們看看如何使用窗口函數(shù)為數(shù)據(jù)集中的每一行分配一個(gè)整數(shù)排名。
. . .
排序函數(shù):ROW_NUMBER() vs RANK() vs DENSE_RANK() 在處理真實(shí)數(shù)據(jù)集時(shí),另一個(gè)常用的概念是記錄排名。公司會(huì)在不同場(chǎng)景中用到排名,例如:
按銷(xiāo)售單位數(shù)排名最暢銷(xiāo)品牌 按訂單數(shù)或產(chǎn)生的收入排名最佳產(chǎn)品類(lèi)別 獲取每個(gè)類(lèi)型中觀看次數(shù)最多的電影名稱 ROW_NUMBER、RANK()和DENSE_RANK()基本上用于為結(jié)果集中指定分區(qū)的每條記錄分配連續(xù)的整數(shù)。
它們之間的區(qū)別在于當(dāng)某些記錄出現(xiàn)并列時(shí)就變得明顯。
當(dāng)結(jié)果表中存在重復(fù)行時(shí),為每條記錄分配整數(shù)的行為和方式會(huì)有所不同。✅
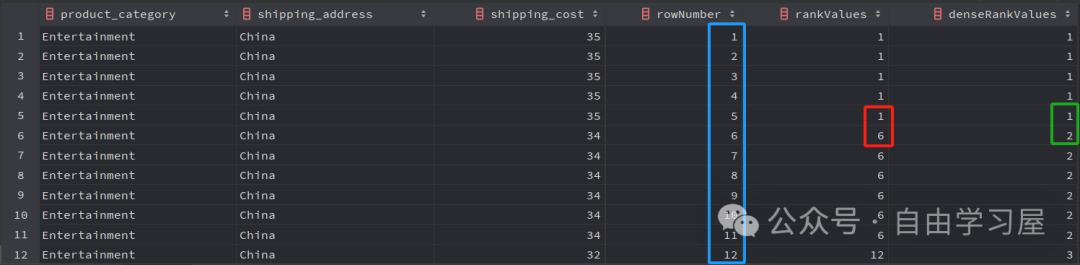
接下來(lái),我們將通過(guò)一個(gè)虛構(gòu)的銷(xiāo)售數(shù)據(jù)集示例,按運(yùn)費(fèi)降序列出所有產(chǎn)品類(lèi)別和送貨地址。
SELECT product_category,OVER PARTITION BY product_category,ORDER BY shipping_cost DESC ) AS rowNumber,RANK () OVER PARTITION BY product_category,ORDER BY shipping_cost DESC ) rankValues,DENSE_RANK () OVER PARTITION BY product_category,ORDER BY shipping_cost DESC ) denseRankValuesFROM dummy_sales_dataWHERE product_category IS NOT NULL AND shipping_address NOT IN ('Germany' , 'India' )AND status IN ('Delivered' );如你所見(jiàn),這三個(gè)函數(shù)的語(yǔ)法都相同,但其輸出卻有所不同,如下所示:
RANK() 函數(shù)根據(jù) ORDER BY 子句的條件檢索排名行。可以看到,前五行之間存在并列,即前五行在 Shipping_Cost 列(在 ORDER BY 子句中提到的列)中的值相同。
RANK 為這五行分配了相同的整數(shù)。然而,它將重復(fù)行的數(shù)量加到重復(fù)的排名上,以獲得下一行的排名。這就是為什么第六行(標(biāo)記為紅色)的 RANK 分配了排名 6(5個(gè)重復(fù)行 + 1個(gè)重復(fù)排名)。
DENSE_RANK 與 RANK 類(lèi)似,但即使行之間存在并列,它也不會(huì)跳過(guò)任何數(shù)字。這可以在上圖的綠色框中看到。
與上面兩個(gè)不同的是,ROW_NUMBER 簡(jiǎn)單地為分區(qū)中的每條記錄按順序分配數(shù)字,從1開(kāi)始。如果它在同一分區(qū)中檢測(cè)到兩個(gè)相同的值,它會(huì)為這兩個(gè)值分配不同的排名數(shù)字。
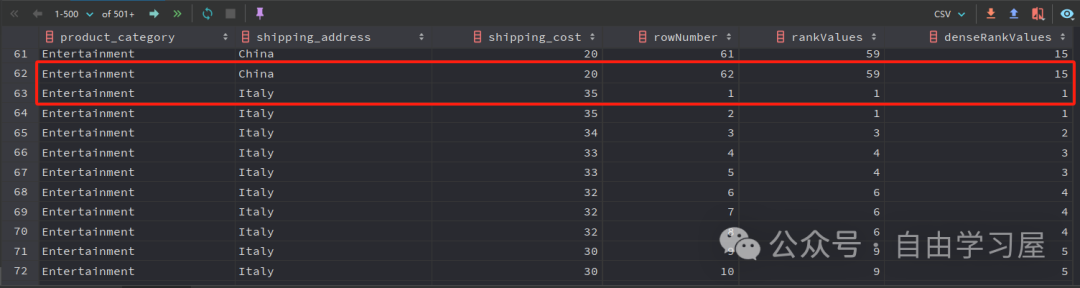
對(duì)于產(chǎn)品類(lèi)別 — 運(yùn)送地址的下一個(gè)分區(qū) → Entertainment — Italy ,三個(gè)函數(shù)的排名都會(huì)重新從1開(kāi)始,如下所示:
如果在 ORDER BY 子句中使用的列中沒(méi)有重復(fù)值,那么這三個(gè)函數(shù)將返回相同的輸出。💯
接下來(lái),下一個(gè)概念將更多地介紹如何使用條件語(yǔ)句和數(shù)據(jù)透視。
. . .
CASE WHEN 語(yǔ)句 CASE語(yǔ)句允許你在SQL中實(shí)現(xiàn)if-else邏輯,因此你可以使用它來(lái)執(zhí)行條件查詢。
CASE語(yǔ)句本質(zhì)上測(cè)試WHEN子句中提到的條件,并返回THEN子句中提到的值。當(dāng)沒(méi)有條件滿足時(shí),它將返回ELSE子句中提到的值。✅
在處理真實(shí)數(shù)據(jù)項(xiàng)目時(shí),CASE語(yǔ)句經(jīng)常用于根據(jù)其他列中的值對(duì)數(shù)據(jù)進(jìn)行分類(lèi)。它也可以與聚合函數(shù)一起使用。
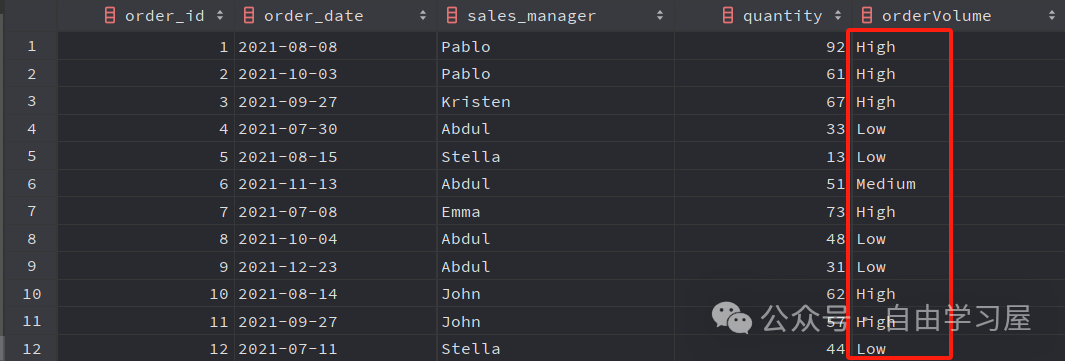
例如,讓我們?cè)俅问褂锰摌?gòu)的銷(xiāo)售數(shù)據(jù),根據(jù)數(shù)量將銷(xiāo)售訂單分類(lèi)為高、中、低量級(jí)。
SELECT order_id,CASE WHEN quantity > 51 THEN 'High' WHEN quantity < 51 THEN 'Low' ELSE 'Medium' END AS orderVolumeFROM dummy_sales_data;
簡(jiǎn)單地說(shuō),它創(chuàng)建了一個(gè)新列 OrderVolume ,并根據(jù) Quantity 列中的值添加了‘High’(高)、‘Low’(低)、‘Medium’(中)等值。
📌 你可以包含多個(gè) WHEN..THEN 子句,并且可以省略 ELSE 子句,因?yàn)樗强蛇x的。
📌 如果你沒(méi)有提到 ELSE 子句并且沒(méi)有條件滿足,查詢將會(huì)為那個(gè)特定記錄返回 NULL。
CASE 語(yǔ)句的另一個(gè)經(jīng)常使用但較少為人知的用途是 — 數(shù)據(jù)透視。
數(shù)據(jù)透視 是一種重新排列結(jié)果集中的列和行的過(guò)程,以便你可以從不同的角度查看數(shù)據(jù)。
有時(shí)你處理的數(shù)據(jù)是長(zhǎng)格式的(行數(shù) > 列數(shù)),而你需要將其轉(zhuǎn)換為寬格式(列數(shù) > 行數(shù))。
在這種情況下,CASE語(yǔ)句非常有用。💯
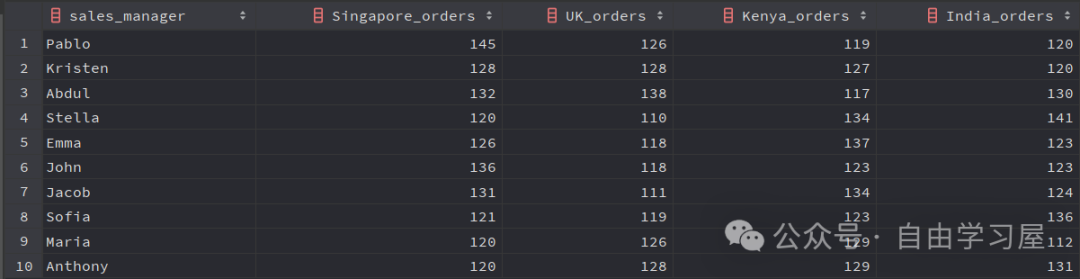
例如,讓我們找出每個(gè)銷(xiāo)售經(jīng)理在新加坡、英國(guó)、肯尼亞和印度處理的訂單量:
SELECT sales_manager,COUNT (CASE WHEN shipping_address = 'Singapore' THEN order_idEND ) AS Singapore_orders,COUNT (CASE WHEN shipping_address = 'UK' THEN order_idEND ) AS UK_orders,COUNT (CASE WHEN shipping_address = 'Kenya' THEN order_idEND ) AS Kenya_orders,COUNT (CASE WHEN shipping_address = 'India' THEN order_idEND ) AS India_ordersFROM dummy_sales_dataGROUP BY sales_manager;使用 CASE..WHEN..THEN,我們?yōu)槊總€(gè)運(yùn)送地址創(chuàng)建了單獨(dú)的列,以獲得以下期望的輸出:
CASE 語(yǔ)句一起使用不同的聚合函數(shù),如 SUM(總和)、AVG(平均值)、MAX(最大值)、MIN(最小值)。
接下來(lái),在處理真實(shí)世界數(shù)據(jù)時(shí),經(jīng)常包含日期時(shí)間值。因此,了解如何提取日期時(shí)間值的不同部分,如月份、周數(shù)、年份,是很重要的。
. . .
根據(jù)日期-時(shí)間列提取數(shù)據(jù) 在許多面試中,面試官可能會(huì)要求你按月聚合數(shù)據(jù)或計(jì)算特定月份的某個(gè)指標(biāo)。
當(dāng)數(shù)據(jù)集中沒(méi)有單獨(dú)的月份列時(shí),你需要從數(shù)據(jù)中的日期時(shí)間變量中提取所需的日期部分。
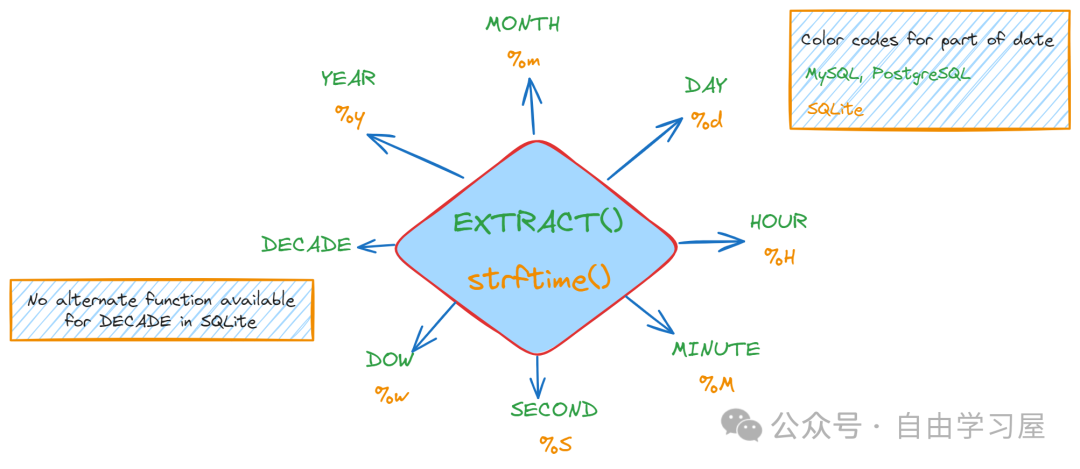
不同的SQL環(huán)境有不同的函數(shù)來(lái)提取日期的部分。通常,在MySQL中,你應(yīng)該了解以下函數(shù):
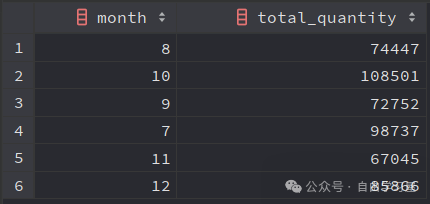
EXTRACT(part_of_date FROM date_time_column_name)比如,使用前面虛擬銷(xiāo)售數(shù)據(jù)集,我們可以計(jì)算每個(gè)月的總訂單量:
SELECT MONTH (order_date) AS month ,SUM (quantity) AS total_quantityFROM dummy_sales_dataGROUP BY MONTH (order_date);
如果你用的是SQLite DB Browser,你需要使用strftime()函數(shù)來(lái)提取日期部分,如下所示。你需要在strftime()中使用%m來(lái)提取月份。
SELECT strftime('%m' , order_date) as month ,SUM (quantity) as total_quantityfrom dummy_sales_dataGROUP BY strftime('%m' , order_date)如果使用EXTRACT()函數(shù),則用以下代碼:
SELECT EXTRACT (MONTH FROM order_date) AS month ,SUM (quantity) AS total_quantityFROM dummy_sales_dataGROUP BY EXTRACT (MONTH FROM order_date);下圖展示了最常提取的日期部分,以及你在使用EXTRACT函數(shù)時(shí)應(yīng)該使用的關(guān)鍵字:
最后但不可或缺的是:
你經(jīng)常會(huì)在現(xiàn)實(shí)世界中看到,數(shù)據(jù)是存儲(chǔ)在一個(gè)大表中,而不是多個(gè)小表中。這時(shí),自連接(SELF JOIN )就派上用場(chǎng)了,它在處理這些數(shù)據(jù)集時(shí)解決了一些有趣的問(wèn)題。
. . .
自連接(SELF JOIN) 與SQL中的其他連接一樣,唯一的區(qū)別就是——在自連接中你是將表和自身進(jìn)行連接。
記住,沒(méi)有SELF JOIN關(guān)鍵字,所以當(dāng)連接中的兩個(gè)表是同一個(gè)表時(shí),你只需使用JOIN。由于兩個(gè)表名相同,在使用自連接時(shí)使用表別名是必要的。✅
編寫(xiě)一個(gè)SQL查詢,找出那些賺得比他們經(jīng)理多的員工 — 這是關(guān)于自連接在面試中最常被問(wèn)到的問(wèn)題之一。
例如,創(chuàng)建一個(gè)像下面的虛擬員工數(shù)據(jù)集(Dummy_Employees):
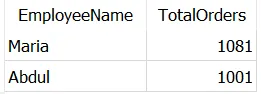
嘗試使用下面這個(gè)查詢找出哪些員工處理的訂單數(shù)量超過(guò)他們的經(jīng)理:
SELECT t1.EmployeeName, t1.TotalOrdersFROM Dummy_Employees AS t1JOIN Dummy_Employees AS t2ON t1.ManagerID = t2.EmployeeIDWHERE t1.TotalOrders > t2.TotalOrders;
正如預(yù)期,它返回了處理的訂單數(shù)量超過(guò)他們經(jīng)理的員工——Abdul和Maria。
幾乎80%的面試中都遇到了這個(gè)問(wèn)題。因此,這是自連接(SELF JOIN)的經(jīng)典案例。
. . .
結(jié)論(Conclusion) 以上就是我想給給大家分享的5個(gè)高級(jí)SQL概念及其實(shí)際應(yīng)用。
希望你能快速讀完這篇文章,并且發(fā)現(xiàn)它對(duì)提升你的SQL技能有所幫助。
晴ERP是一款針對(duì)中小制造業(yè)的專(zhuān)業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國(guó)內(nèi)大量中小企業(yè)的青睞。")
晴PMS碼頭管理系統(tǒng)主要針對(duì)港口碼頭集裝箱與散貨日常運(yùn)作、調(diào)度、堆場(chǎng)、車(chē)隊(duì)、財(cái)務(wù)費(fèi)用、相關(guān)報(bào)表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點(diǎn),圍繞調(diào)度、堆場(chǎng)作業(yè)而開(kāi)發(fā)的。集技術(shù)的先進(jìn)性、管理的有效性于一體,是物流碼頭及其他港口類(lèi)企業(yè)的高效ERP管理信息系統(tǒng)。")
晴WMS倉(cāng)儲(chǔ)管理系統(tǒng)提供了貨物產(chǎn)品管理,銷(xiāo)售管理,采購(gòu)管理,倉(cāng)儲(chǔ)管理,倉(cāng)庫(kù)管理,保質(zhì)期管理,貨位管理,庫(kù)位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號(hào)管理軟件。")
晴免費(fèi)OA是一款軟件和通用服務(wù)都免費(fèi),不限功能、不限時(shí)間、不限用戶的免費(fèi)OA協(xié)同辦公管理系統(tǒng)。")


 400 186 1886
400 186 1886
晴公司官網(wǎng)")


 根據(jù)你的使用情況,你也可以與
根據(jù)你的使用情況,你也可以與