大數據分頁實現與性能優化
當前位置:點晴教程→知識管理交流
→『 技術文檔交流 』
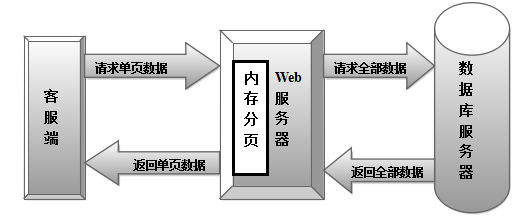
摘要:Web 應用程序中經常使用數據分頁技術,該技術是提高海量數據訪問性能的主要手段。實現web數據分頁有多種方案,本文通過實際項目的測試,對多種數據分頁方案深入分析和比較,找到了一種更優的數據分頁方案Row_number()二分法。它依靠二分思想,將整個待查詢記錄分為2部分,使掃描的記錄量減少一半,進而還通過對數據表及查詢條件進行優化,實現了存儲過程的優化。根據Row_number()函數的特性,該方案不依賴于主鍵或者數字字段,大大提高了它在實際項目中的應用,使大數據的分頁效率得到了更顯著的提高。 在web應用程序開發過程中,不可避免的要頻繁查詢數據庫中的數據。隨著互聯網的飛速發展,中大型系統的數據量變得龐大而復雜,要提高系統的響應性能,就需要降低客服端和服務器端數據的傳輸量,因此大數據分頁的功能不可或缺。若選擇一個不合理的數據分頁方案,大數據在查詢時就會引發網絡資源嚴重浪費【1】,網站擁堵,查詢界面等待時間過長等一系列嚴重影響系統性能的問題。所以,一個有效的大數據分頁方案對于系統的性能而言至關重要。解決大數據分頁的問題,不同的人會采用不同的方法,其訪問性能各有優劣。筆者通過比較多種分頁研究方案【2】,根據實際案例的測試結果,綜合分析各種分頁方案的利弊,揚長避短,最終找到一種更優于以往的分頁方案,Row_number()二分法。二分思想在計算機中早有應用,二分查找算法就是二分思想的具體體現,將它引入到存儲過程中,依靠二分法的思想,對Row_number()存儲過程分頁進行優化設計,從而加快查詢速度,提高大數據的分頁效率。 1、動態網頁數據分頁 Web數據分頁是基于降低數據傳輸量來提高服務響應時間的分頁方法。但是不同的數據分頁方法,帶給Web主機的系統I/O訪問性能是不同的。無論是JAVA平臺,還是.NET平臺,對數據的分頁都提供了多種方法,主要分為2大類:一類是內存數據分頁,一類是數據源分頁。 1.1內存數據分頁 所謂內存數據分頁【3】就是當客戶端向 Web服務器發出查詢請求時,Web 服務器響應請求并構建 SQL 語句發送到數據庫服務器,數據庫服務器執行 SQL 語句并返回整個結果集給 Web 服務器,Web 服務器再執行內存數據分頁操作并把該頁數據發往客戶端,完成一次查詢。內存數據分頁的流程如圖1所示:
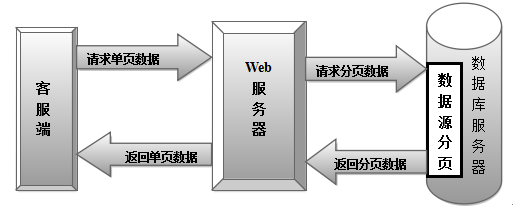
圖1內存數據分頁 內存數據分頁的優點是編程上容易實現,對于少量數據檢索效率高,能提高開發者開發的效率。缺點是使用內存數據分頁機制時,首先需要把所有的數據庫記錄調入內存。調入數萬條記錄進入內存本身需要消耗大量時間,所以當數據量超過百萬時,數據訪問性能急劇下降,幾乎讓Web服務器的系統I/O不堪重負,對于大型系統而言,內存數據分頁不能滿足基本性能的要求。 對于內存數據分頁,在.NET平臺下常用的分頁方案是GridView控件自帶的分頁【4】,GridView是DataGrid的后繼控件, GridView和DataGrid功能相似,都是在web頁面中顯示數據源中的數據,將數據源中的一行數據,也就是一條記錄,顯示為在web頁面上輸出表格中的一行。GridView控件功能強大,對于分頁操作簡單容易。 利用GridView控件自帶的分頁功能實質是把查詢的所有數據從后臺讀取出來,然后通過內存分頁的方式返回單頁數據,因此第一頁和最后一頁的顯示速度基本相同。常用的查詢語句為:Select * from @TableName. 1.2數據源分頁 數據源分頁【4】是在數據庫服務器上實現截取請求頁數據的分頁操作,在 Web 服務器上無需做分頁操作。數據源分頁一般采用存儲過程[5]的方式,由于存儲過程是在數據庫服務器中預先編譯的,訪問存儲過程時只需給出存儲過程名及參數即可,往返的數據量非常小安全性也更高。數據源分頁機制的執行流程如圖 2所示。客戶端向 Web服務器發出查詢請求,Web 服務器響應請求,通過連接到服務器數據庫執行存儲過程,同時返回請求頁記錄給 Web 服務器,Web 服務器再把該頁數據發往客戶端,完成一次查詢。
圖2 數據源分頁 數據源分頁的優點是減輕 Web 服務器和數據庫服務器的負擔,在大數的處理上保證了高效率的分頁功能。缺點是分頁方法必須由開發人員編程實現,過程較為復雜。 對于數據源分頁,人們提出了使用臨時表或表變量的方法來提升訪問主鍵字段的效率,其效率也相當高。目前常用到的數據源分頁方案有如下五種:首先說明幾個變量:@ PageSize表示分頁大小,默認值為10;@TableName表示分頁表的名稱;@ IDField表示分頁表的排序字段;@ PageIndex表示當前為第幾個分頁,默認值為1。 1、Select top and Not in分頁:此分頁方案的基本思想就是利用id自增數字字段連續不間斷時通過分頁傳遞的參數實現分頁信息的顯示,其通用的存儲過程寫法為:SelectTop @PageSize* from @TableNamewhere(@ IDField not in (SelectTop @PageSize* (@PageIndex-1) @ IDField from @TableName order by @IDField))order by @IDField. 2、Select top and Max()分頁:根據Max()函數的性質,在分頁時依賴于數據表的id自增數字段,首先得到排序后的id記錄值;然后利用Max()來得到待分頁需要的最大記錄;最后根據id值得到分頁記錄信息。這種方式避免了全表掃描的大量I/O操作,其效率相當高。 其通用的存儲過程寫法為:select top '+str(@pageSize)+' * From @TableName where (@ IDField >(select max(@ IDField) From (select top '+str(@pageSize*@pageIndex)+' @ IDField From @TableName order by @ IDField asc) as TempTable)) order by @ IDField asc . 3、Row_number()分頁:Row_number()函數是sql sever2005數據庫推出的新功能函數,它的功能是返回結果集分區內行的序列號,每個分區的第一行從 1 開始。其分頁存儲過程寫法為:select* from (select*,Row_Number() over(orderby @IDField) asRowNumber from @TableName ) asTempTable where RowNumber between (@ PageIndex - 1) * @ PageSize + 1 and @PageIndex* @ PageSize. 4、游標分頁:游標提供了一種對從表中檢索出的數據進行操作的靈活手段,就本質而言,游標實際上是一種能從包括多條數據記錄的結果集中每次提取一條記錄的機制。游標總是與一條TSQL 選擇語句相關聯因為游標由結果集(可以是零條、一條或由相關的選擇語句檢索出的多條記錄)和結果集中指向特定記錄的游標位置組成。其通用的存儲過程寫法為:declare @P1 int, --P1是游標的id,@rowcount int,@str=’select * from @TableName’,exec sp_cursoropen @P1 output,@str,@scrollopt=1,@ccopt=1,@rowcount=@rowcount output,set @ PageIndex=(@PageIndex-1)*@pagesize+1,exec sp_cursorfetch @P1,16, @ PageIndex,@pagesize,exec sp_cursorclose @P1. 5、selectMax()結合臨時表:臨時表【6】是一種因為暫時需要而創建的數據表,主要用來臨時存儲數據處理的中間結果。利用該方案的優點是可以擺脫對于數字字段的依賴,能夠更方便的應用于實際項目的分頁。其通用存儲過程的語句為:declare @indextable table(id int identity(1,1),nid int) --定義表變量insert into @indextable(nid) select @IDField From @TableName order by @IDField asc;select top (@pageSize) * from @TableName O,@indextable t whereO.bid=t.nid and (id>(select max(id) From(selecttop(@pageSize*@pageIndex) id From @indextable order by id asc) as TempTable)) order by id asc. 1.3 ASP.NET實現數據源分頁的調用 利用ASP.NET提供的DataSet類可輕松的實現數據源分頁方案的調用,調用存儲過程核心代碼如下: 1.4現有分頁方案的不足 對于上述方案中的select top and NotIn和select top and Max()分頁方案,在實際的項目中很難應用。根據NotIn()和max()函數的分頁原理,可以發現這兩種分頁方案存在致命的不足,就是依賴于數據表里的id自增數字字段,并且這些自增數字必須要具有連續性,如果刪除數據表里的一條或多條數據,id數字字段不再連續,那樣分頁的每一頁數量就會變得大小不一,這種嚴格依賴于id自增數字字段的分頁方案適用性差,對于數據表中沒有數字字段或主鍵不能按數字大小排序的分頁更是一籌莫展,所以,這樣的分頁方案局限性大,不能廣泛應用實際項目。而內存分頁GridView和傳統的游標分頁在大數據的分頁上更是嚴重耗時,不能達到實際網頁響應的時間要求。對于max()結合臨時表這種適應性強的分頁方案,在后期大數據的處理上難以保證時間的效率,隨著數據量的不斷增大,在構建中間臨時表的時候,插入主鍵列數據到臨時表時就會用去越來越多的時間,同時,又額外的開銷了臨時表和數據表匹配的時間。同max()結合臨時表一樣,Row_number()函數在大數據后期分頁時顯示的效率也并不理想,這兩種分頁方案更適用于中小型的數據分頁,要保證大數據的分頁效率,就需要用到新的分頁方案,Row_number()二分法。 2、Row_number()二分法簡介與優化 2.1簡介 Row_number()二分法利用二分法的設計思想,此方法最大的特點在于它縮小了查詢時數據掃描的范圍。由于需要返回查詢結果的記錄數,若利用select@ RecordCount=count(* ) from +@ Ta-bleName+@ strWhere0語句返回記錄數,進行大數據量查詢統計時這個語句將耗費大量時間,這會降低系統分頁的性能。所以,為了避免統計記錄帶來的系統整體性能的下降,將統計記錄分離為獨立存儲過程,只在系統加載時統計1次,然后把統計結果以參數的方式傳遞給Row_number()二分法的存儲過程,這樣將大大提高分頁的效率。根據Row_number()函數的分頁原理,建立Row_number()二分法分頁并不難,其通用存儲過程為(@sum為獨立存儲過程統計的返回結果):Declare @orderStr varchar(244),if @pageSize*@pageIndex>@sum/2 @orderStr=order by @IDField desc ,else @orderStr=order by @IDField asc,select* from (select*, Row_Number() over(@orderStr) asRowNumber,From @TableName ) asTempTable where RowNumber between (@ PageIndex - 1) * @ PageSize + 1 and @PageIndex* @ PageSize. 2.2優化 對于上文提到的Row_number()二分法分頁方案,在系統中還需要數據庫的合理設計和sql語句的優化。對于上百萬的數據查詢,要提高查詢的效率,就要用到數據庫中的索引【7】,合理應用索引會讓查詢速度達到成倍的提高。索引分為聚集索引和非聚集索引兩種類型,聚集索引在大數據量的查詢中,查詢的速度快于非聚集索引。所以,在大數據量的分頁時,應采用聚集索引。由于聚集索引在一個數據表里只有一個,這個聚集索引的資源也就顯得格外的寶貴,主鍵的默認設置為聚集索引,而很多時候查詢的條件,排序的條件并不是主鍵字段,所以應該修改主鍵字段的設置,把它設置為非聚集的索引。 例如:以人員信息表mess(id,name,phone,number,work,hometown,email,time)做測試,id列為主鍵,設置為非聚集的類型,time為排序列,設置為聚集索引,這樣在做人員信息的查詢時,就會按照時間的索引,快速的找到查詢的信息。一般對于多條件查詢,可以把多個查詢的條件集合在一起設置成為一個聚集索引。以上是僅對于一個數據表查詢時建立索引的原則。當涉及到多個數據表時,可按如下案例建立索引:mess(id,name,phone,number,work,hometown,email,time),user(userid,password,power)其中mess為人員信息表,user為密碼權限表。現在要查詢人員的信息和權限,需要兩表連接查詢。查詢語句為:select * from mess,user,where user.userid=mess.id order by time。根據這個查詢語句,為了提高兩表的連接效率,應把userid字段和id字段先建立外鍵關系。根據返回的結果的需要,按照時間排序,對于mess表,依舊以id列為主鍵,time列結合id列為聚集索引,對于user表,因為匹配的條件為useid,要獲得人員的權限,應該以userid為聚集索引查詢power列,這樣兩個表都建立了屬于各種的索引,能夠快速的查詢到相關信息,從而達到整體的查詢效率提高的目的。對于多表匹配時,在相應的單表里建立合理的索引能使查詢速率達到事半功倍的效果。 同數據庫的設計一樣,sql語句的優化一樣有助于提高分頁的效率。通過測試比較,一個查詢條件直接用等號匹配的速度高于用 like+%的匹配速度。例如要在前臺根據條件查詢信息表中人員的姓名,工作和籍貫,若是用一句sql語句可以寫成:Select * from mess Where name like @name+’%’ and work like +@work+’%’ and home like @home+’%’。但是試想一下,擁有百萬的數據一次一次的像上述sql語句那樣like匹配,這樣會因為大量的匹配消耗寶貴的時間。所以,存儲過程中的sql語句,最好分情況而定:通過查詢條件的不同動態匹配sql語句,例如:If(name.text!=””) {sql=select * from messWhere name = @name},If(name.text==””&&work.text!=””&&status.text!==””) {sql=select * from messWhere status = @status and work = @work}。對于多表涉及到的多條件查詢,應該把查詢范圍小的寫在查詢條件的前面,這樣可以縮小篩選的范圍,減少后面條件匹配的范圍,從而降低查詢的所用時間。如select * from mess,user,where user.userid=mess.id and user.name=’a’ order by time,這樣的sql語句應該優化改下為select * from mess,user,where user.name=’a’ and user.userid=mess.id order by time.同理,對于多表之間的匹配,也遵循匹配結果范圍小的兩個數據表優先匹配。 3、性能實驗分析 3.1測試平臺 數據庫:sql sever2008 數據表:人員信息表mess(bid,name,phone,number,work,hometown,email,time)物理大小:103MB,共有一百萬零三條數據記錄。中鐵建企業管理生產計劃統計系統中的項目表和施工單位表,項目表的物理大小在數據量為100萬條時為375.25MB,施工單位表共包括998個各級施工單位,物理大小為0.07MB。 查詢要求: 1.查詢mess表中的所有記錄,每頁返回十條記錄結果。 2.查詢中鐵建企業管理生產計劃統計系統中的項目表和施工單位表,返回項目的編號,項目的施工單位編號,施工單位的名稱,項目的名稱,項目的類型,項目的合同額,項目的開累數,項目的剩余開累數,及錄入員,每頁返回十條記錄結果。 測試環境:華碩筆記本電腦K43T,CPU:A6-3400M,內存:2G。 操作系統:win7旗艦版 3.2測試結果 根據查詢要求1記錄各分頁方案的所用時間: 表1數據表mess共有100萬條數據 ms
根據查詢要求2記錄各分頁方案的所用時間(其中select top and NotIn和select top and max分頁方案因為局限性不能對查詢數據分頁): 表2項目表和施工單位表共有210萬條數據 ms
通過表1,表2的數據,可以發現Row_number()二分法是上述所有分頁研究方案中效果最好的分頁方案,由于Row_number()函數本身并不依賴數據表中的數字段,所以它可以在實際項目中廣泛的應用,真正的提高了大數據的分頁效率。特別聲明:由于筆者所用的測試電腦本身的硬件低端,CPU處理速度慢,遠不及真正的服務器的處理速度,所以,在真正的服務器上即使是千萬頁的信息讀取也是高效迅速的。 4、結束語動態網頁設計中分頁顯示數據有多種實現方法,本文通過上述七種分頁方案的實驗測試,比較各種分頁方案的優缺點,一步一步的分析推導,提出了最優的分頁方案Row_number()二分法,通過實際項目的測試,利用該方案能夠充分提高大數據分頁的效率,此方案對解決中大型系統的數據分頁具有一定的指導意義。 參考文獻: [1] 洪新建,張陽,洪新華.對Web數據查詢分頁顯示的設計與實現[J]. 電腦開發與應用, 2007, 6(6): 44. [2] 付文平,羅鍵.基于Web的分頁技術的設計與實現[J]. 計算機時代, 2007(10): 55. [3]張素智,劉中鋒.基于ASP. NET的Web數據分頁實現與性能優化[J].鄭州輕工業學院學報(自然科學版),2010( 06) . [4]陳南. ASP. NET 中大數據量分頁技術的研究與實現[J].計算機應用與軟件,2011( 04) . [5] 陳煥通,陳堯妃.基于存儲過程的數據快速分頁方法[J].軟件導報,2008( 12) . [6]胡配祥,張成叔,陳良敏.SQL臨時表在科研管理系統數據處理中的應用[J].洛陽理工學院學報 (自然科學版),2011( 06) . [7] 陳偉柱,蘇中,張俐,王睿. 索引和查找方法 [P]. 中國專利:CN1979469,2007-06-13.
文章出處:http://www.cnblogs.com/wlandwl/p/paginaction.html 該文章在 2024/6/6 10:28:49 編輯過 |
關鍵字查詢
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886