SQL數據庫使用號段模式實現分布式ID
當前位置:點晴教程→知識管理交流
→『 技術文檔交流 』
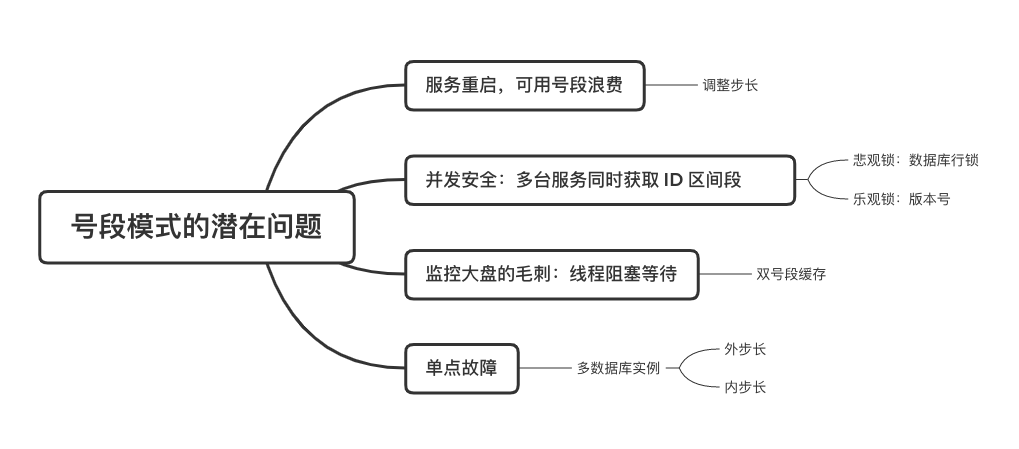
在單體系統時代,程序常被部署在單個物理機中,數據被存儲在單個數據庫中,我們可以采取數據庫的自增 ID 來實現 ID 的全局唯一。 現在,系統開始從單體系統演變為分布式系統,當業務量和數據量增長之后,我們會選擇分庫分表。同時,隨著微服務的推廣與普及,我們的服務變得越來越多。 當然,在復雜的分布式系統中,我們同樣需要對大量的數據進行唯一標識,而數據庫的自增 ID 顯然已經不能滿足需求了。此時,我們就需要通過其他手段實現全局唯一 ID 了。 事實上,實現分布式全局唯一的 ID 有許多方案,包括基于 Redis 實現分布式 ID 方案、UUID、數據庫號段模式、雪花算法等。但今天我們學習如何通過號段模式實現分布式 ID?為什么選擇了“號段模式”。要回答這個問題,你需要先知道業務系統對分布式 ID 到底有要求? 在我看來,業務系統對分布式 ID 的要求,主要是 4 個包括:全局唯一性、趨勢遞增、單調遞增和信息安全。接下來,我就和你一一分析下。 第一, 全局唯一性。確保 ID 的全局唯一性,是最基本的要求。 第二, 趨勢遞增。 趨勢遞增指的是,我們的分布式 ID 是呈增長趨勢的,但是序列之間是不連續的。事實上,MySQL 的 InnoDB 引擎使用的是聚集索引,底層的數據結構是 B+ 樹,使用有序的主鍵可以保證寫入性能。 這也是為什么我們不提倡使用 UUID(Universally Unique Identifier,通用唯一識別碼)作為 ID 的原因:UUID 的無序性,會導致新增數據的時候不是順序的,從而出現頻繁的頁分裂,嚴重影響性能。 第三, 單調遞增。我們要保證 ID 的增長不僅有序,而且還要單調遞增,即下一個新增的 ID 一定大于上一個存在的 ID,從而保證能支持事務版本號、排序等場景。 第四, 信息安全 。 在一些應用場景下,我們需要 ID 有不規則性,確保它難以被猜測。例如,訂單號,我們就需要確保它不是順序遞增的,不然,就很容易被競爭對手猜測出我們一天的訂單量。 號段模式滿足全局唯一性、趨勢遞增、單調遞增三個要求,所以我選擇了號段模式。而信息安全的要求,例如訂單號場景,我們常常會采用雪花算法來實現。那么,如何通過號段模式實現分布式 ID? 使用號段模式如何實現分布式 ID?想一想,我們在數據庫中創建一張全局 ID 序列表。例如,這張表叫做 common_sequence,它有 id、name、value、gmt_modified 四個字段。需要注意的是,每個業務用 name 字段來區分,每個 name 的 ID 獲取是相互隔離、互不影響的。 當我們需要為某個表生成主鍵 ID 時,就從序列表中分配全局主鍵 ID。 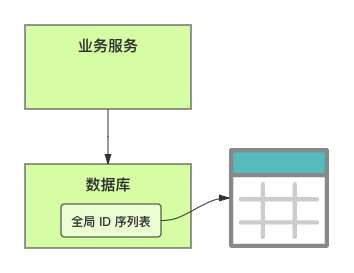 例如,我們新增一個客服工單,需要自增一個 ID。在這里,我們在全局 ID 序列表中,存入 name 等于 task 的記錄,它的值是 1,也就是說,這個業務表的自增 ID 的當前值是 1。 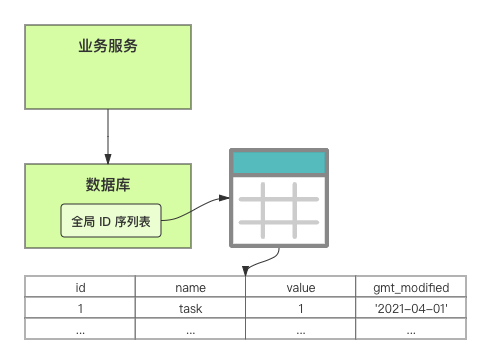 但是,如果我們每次獲取 ID 都需要讀寫一次數據庫,就會對數據庫造成比較大的壓力。那么,有什么比較好的優化方案呢? 事實上,我們可以做一個小優化:每次向全局 ID 序列表獲取 一批 ID,然后存入 JVM 本地緩存中慢慢使用;當這批 ID 被消耗完了,再向全局 ID 序列表重新發起一次讀寫請求。這里,從全局 ID 序列表中申請的一批可用的 ID,我們稱之為 ID 號段。 ID 分段之后,我們再來看看整體流程。 在新增客服工單時,我們會向全局 ID 序列表申請的可以使用的號段。假設,我們需要預申請 5000 個 ID。首先,客服工單服務會先查詢全局 ID 序列表,獲取當前 name 等于 task 的記錄的最新值是多少。這里,最新值是 1。 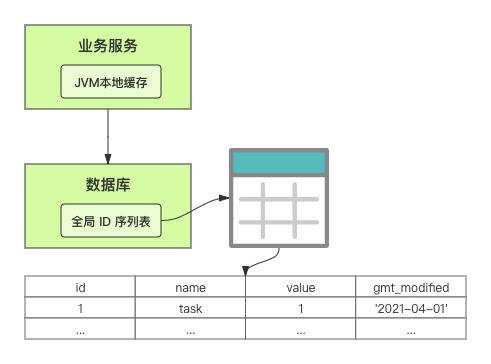 然后呢,全局 ID 序列表更新相對應的記錄值。它把最新值 +5000,也就是 5001,存儲起來。 緊接著,客服工單服務將可以使用的號段存儲在 JVM 本地緩存中,即為[1, 5000]。客服工單服務在區間[1, 5000]中依次獲取 ID。 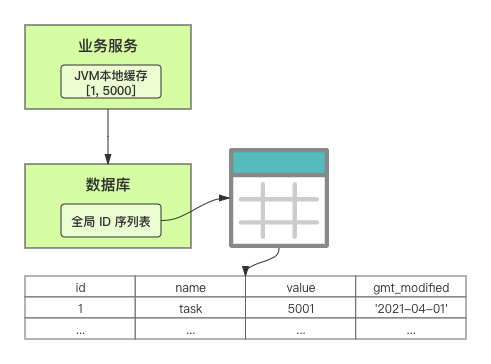 如果客服工單服務把區間的值用完了,再去請求全局 ID 序列表,獲取到可以用的[5001, 10000]區間的 ID。 通過這個方案,我們用完號段之后再去數據庫獲取新的號段,可以大大減輕對數據庫的依賴及給數據庫造成的壓力。 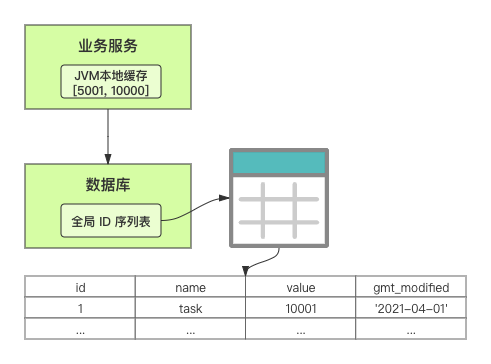 總結一下, 號段模式每次向全局 ID 序列表獲取一批可以使用的 ID 號段,然后存入 JVM 本地緩存中。 其中,我們需要預申請 5000 個 ID 中的“5000”,我們稱為 步長。當這批號段被消耗完了,我們再向全局 ID 序列表重新發起一次讀寫請求。當 5000 個 ID 被消耗完了之后,才會重新讀寫一次數據庫。因此,讀寫數據庫的頻率從 1 減小到了 1/5000。 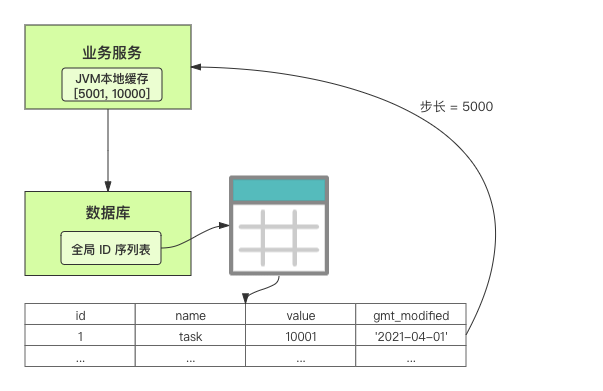 號段模式 不僅提升了數據庫讀寫性能,還很方便我們做橫向的線性擴展。 假設,我們部署 3 臺客服工單服務,它們分別申請可用的[5001, 10000]、[10001, 15000]、[15001, 20000]號段。然后呢,全局 ID 序列表將該業務的自增 ID 可用值更新為 20001。多臺客服工單服務之間憑借號段生成算法的原子性,保證每臺服務上的可用號段不會重復,從而使得 ID 全局唯一。 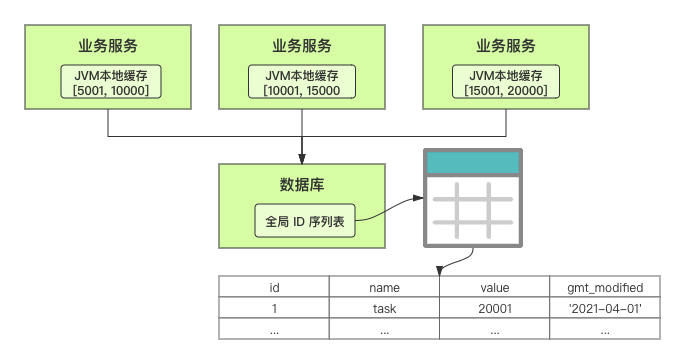 使用號段模式實現分布式 ID,有哪些常見問題?想一想,這個流程會不會存在什么潛在問題?事實上,會的。 服務重啟,可用號段浪費我們遇到的第一個問題是,如果某臺客服工單服務重啟了,那么該號段就作廢了。因此,我們需要 特別注意步長的配置,盡可能減少可用 ID 的浪費。 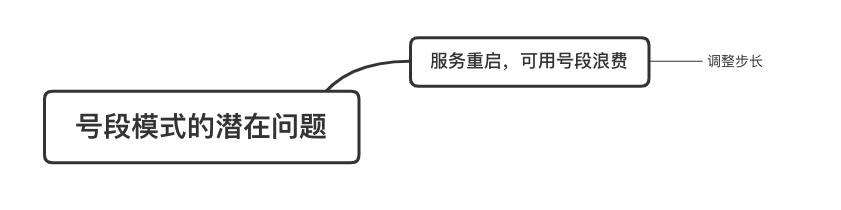 但是呢,減少步長的大小,間接的就會提升數據庫的性能壓力,因為數據庫的讀寫數據庫的頻率是 1/步長。 因此,步長的配置需要一個折中的配置策略。我們可以用觀測平時的業務峰值,和大促時的業務峰值,來動態配置步長。此外,由于重啟導致的可用 ID 的浪費,也會造成 ID 不是連續的,不過,這對于大部分業務都是可接受的。 并發安全:多態服務同時獲取 ID 區間段我們遇到的第二個問題是,如果是多臺服務同時獲取號段,可能會發生競爭問題。 其實呢,我們可以 使用悲觀鎖來解決。最容易實現的方案就是,用數據庫自身的行鎖。數據庫行鎖在數據處理過程中,將數據處于鎖定狀態,來保證數據訪問的排他性。 如果考慮到數據庫的悲觀鎖會阻塞等待,我們也可以考慮 給全局 ID 序列表加一個版本號,通過樂觀鎖的方式來實現。也就是說,每次更新都加上版本號,保證并發更新的正確性。 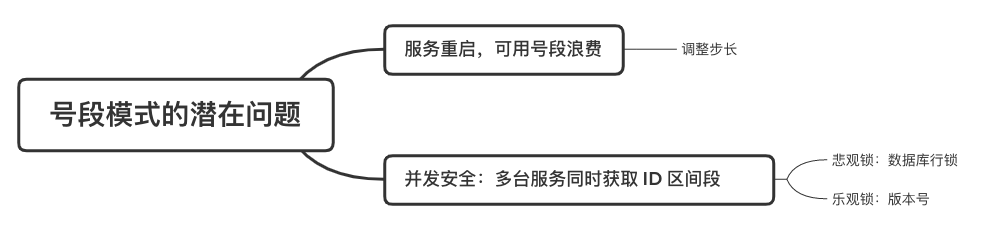 監控大盤的毛刺:線程阻塞等待我們遇到的第三個問題是,當服務消費完號段之后,向全局 ID 序列表重新發起讀寫請求時,在這個臨界點可能會發生線程阻塞在數據庫取回號段的等待,它帶來的表象就是監控大盤上的偶爾會出現的毛刺。 對于這個問題,業界提出了 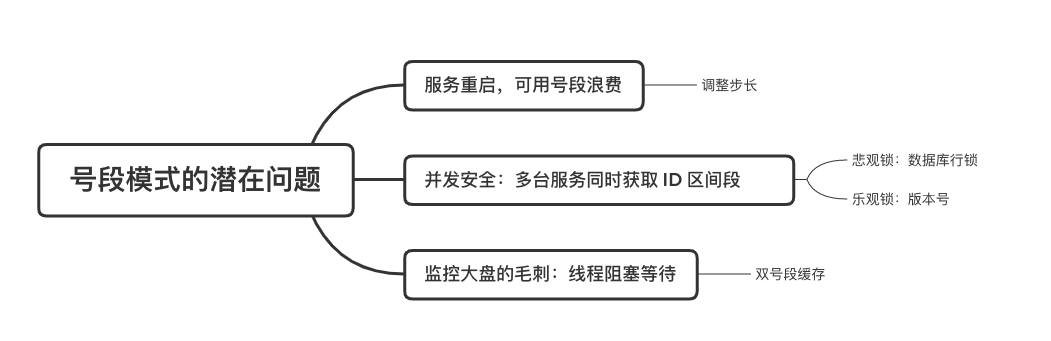 雙號段緩存方案 的思路是,在號段快用完的時候,我們異步加載下一個可以使用的號段,保證 JVM 本地緩存中始終有可用的號段。因此,我們就不需要等到號段用完的時候才去更新號段,以此來避免性能波動。 事實上,雙號段緩存方案中,服務內部的緩存區有兩個號段:號段 A 和號段 B。當前號段 A 用到一定程度的時候,如果下一個號段 B 還未更新,則服務開啟一個線程異步更新下一個號段 B。 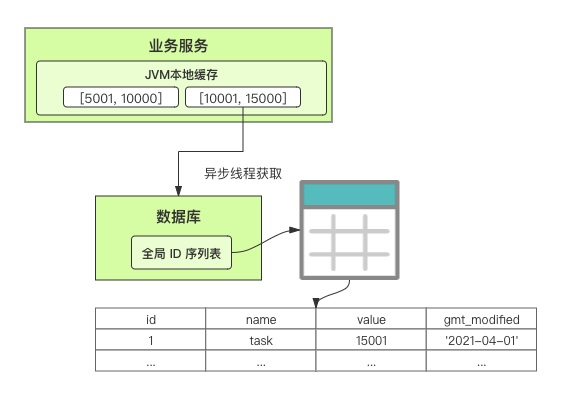 當前號段 A 全部消耗完之后,同時,下一個號段 B 準備好了,那么把緩存區中的號段 A 與號段 B 切換,也就是說,當前可用號段 A 變成了號段 B,如此反復循環切換。 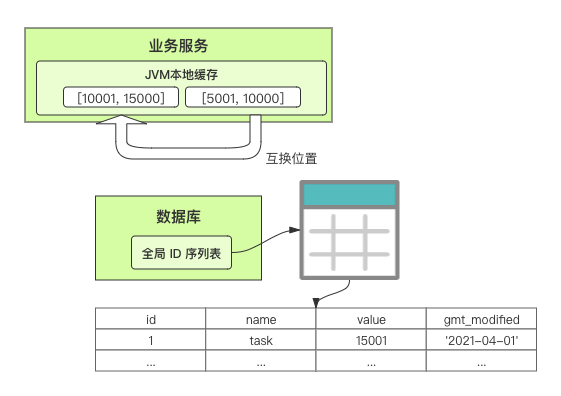 單點故障我們遇到的第四個問題是,數據庫只有一個實例時,會存在單點故障。也就是說,如果數據庫不可用,則獲取號段不可用。因此,我們還要支持多數據庫實例。 這個時候,我們還需要引入兩個新的概念, 外步長和內步長:
 這里,有一個公式來計算新值。這個新值,是用來計算號段的生成區間。 我舉一個案例。假設有兩個數據庫實例,我們設置外步長是 1000,內步長也是 1000。客服工單服務向數據庫 1 申請可用的[1, 1000]號段。  當 1000 個 ID 被消耗完了之后,再重新讀寫一次數據庫,正好此時路由到了數據庫 2,然后呢,數據庫 2 分配可用的[1001, 2000]號段,然后根據計算公式把自己的值更新為 2001。 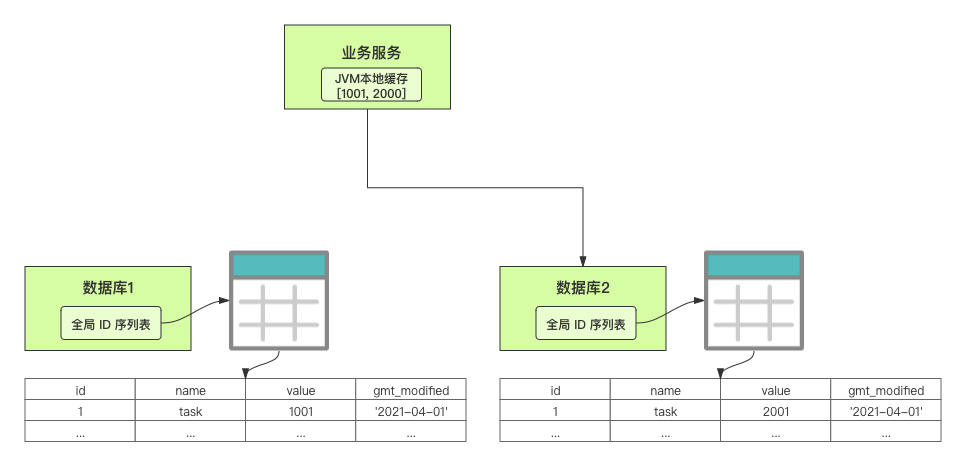 總結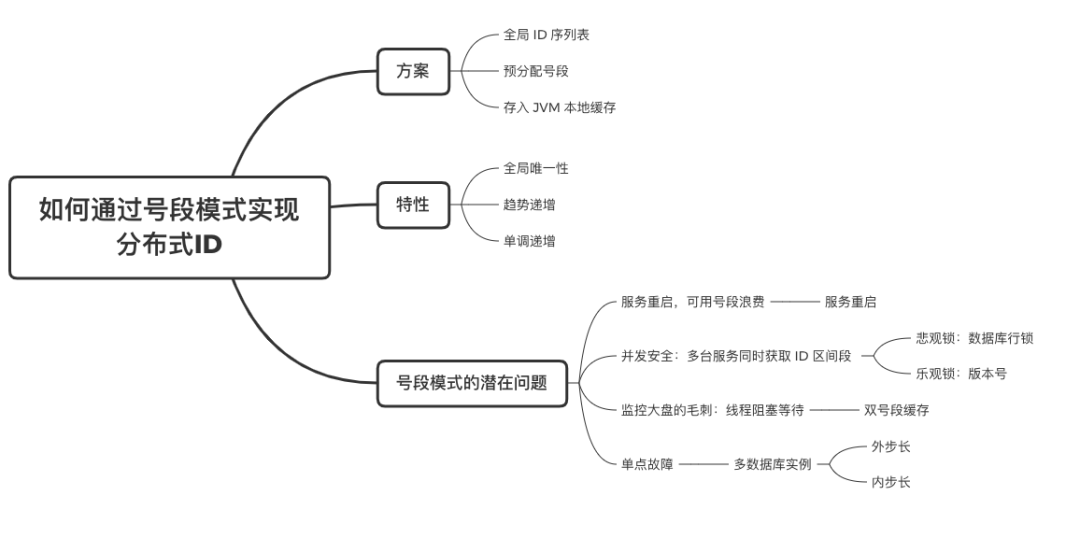 我們圍繞如何通過號段模式實現分布式 ID 進行了討論。號段模式滿足全局唯一性、趨勢遞增、單調遞增三個要求。 首先,我們需要了解號段模式,它通過每次向全局 ID 序列表獲取一批可以使用的號段,然后存入 JVM 本地緩存中使用,當這批號段被消耗完了,再向全局 ID 序列表重新發起一次讀寫請求。 在具體實現中,使用號段模式還有 4 個潛在問題:
該文章在 2024/10/23 9:57:19 編輯過 |
關鍵字查詢
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886


