在數(shù)據(jù)庫查詢中,count(*) 和 count(1) 是兩個常見的計數(shù)表達式,都可以用來計算表中行數(shù)。
很多人都以為 count(*) 效率更差,主要是因為在早期的數(shù)據(jù)庫系統(tǒng)中,count(*) 可能會被實現(xiàn)為對所有列進行掃描,而 count(1) 則可能只掃描單個列。
但事實真是如此嗎?
執(zhí)行原理
先來看看這兩者的執(zhí)行原理:
count(*) 查詢所有滿足條件的行,包括包含空值的行。在大多數(shù)數(shù)據(jù)庫中,count(*) 會直接統(tǒng)計行數(shù),并不會實際去讀取每行中的詳細數(shù)據(jù),因為數(shù)據(jù)庫引擎會自行優(yōu)化該計數(shù)操作,以提高執(zhí)行效率。
count(1) 也是計算表中的行數(shù),這里的 1 是一個常量,只是作為一個占位符,并沒有實際的含義。與 count(*) 類似,數(shù)據(jù)庫引擎也會對 count(1) 進行優(yōu)化,以快速確定表中的行數(shù)。
count(*) 和 count(1) 的 性能差異
再說性能,在大多數(shù)數(shù)據(jù)庫中,其實 count(*) 和 count(1) 的性能非常相似,甚至可以說沒有區(qū)別,這是因為大多數(shù)數(shù)據(jù)庫引擎對這兩種計數(shù)方式進行相同的優(yōu)化,并沒有明顯的執(zhí)行效率上的差異。但是在特殊情況下可能會有細微的差異,造成這種差異的原因通常有以下幾種:
1. 數(shù)據(jù)庫引擎的差異
不同的數(shù)據(jù)庫引擎可能對 count(*) 和 count(1) 采取不同的優(yōu)化策略,這在某些情況下可能會導(dǎo)致兩種計數(shù)方式的性能差異。例如:
-
- SQL Server:在某些版本的 SQL Server 中,
count(1) 在特定的查詢計劃中可能稍微快一些,但這種差異通常微乎其微,只有在處理非常大的表或復(fù)雜查詢時才會顯現(xiàn)出來。 -
- MyISAM 引擎:在不附加任何
WHERE 查詢條件的情況下,統(tǒng)計表的總行數(shù)會非常快,因為 MyISAM 會用一個變量存儲表的行數(shù)。如果沒有 WHERE 條件,查詢語句將直接返回該變量值,使得速度很快。然而,只有當(dāng)表的第一列定義為 NOT NULL 時,count(1) 才能得到類似的優(yōu)化。如果有 WHERE 條件,則該優(yōu)化將不再適用。 -
- InnoDB 引擎:盡管 InnoDB 表也存儲了一個記錄行數(shù)的變量,但遺憾的是,這個值只是一個估計值,并無實際意義。在 Innodb 引擎下,
count(*) 和 count(1) 哪個快呢?結(jié)論是:這倆在高版本的 MySQL 是沒有什么區(qū)別的,也就沒有 count(1) 會比 count(*) 更快這一說了。 -
另外,還有一個問題是 Innodb 是通過主鍵索引來統(tǒng)計行數(shù)的嗎?
如果該表只有一個主鍵索引,沒有任何二級索引的情況下,那么 count(*) 和 count(1) 都是通過通過主鍵索引來統(tǒng)計行數(shù)的。
如果該表有二級索引,則 count(*) 和 count(1) 都會通過占用空間最小的字段的二級索引進行統(tǒng)計。
2. 索引的影響
如果表上有合適的索引,無論是count(1) 還是 count(*) 都可以利用索引來快速確定行數(shù),而不必掃描整個表。在這種情況下,兩者的性能差異通常可以忽略不計。例如,如果有一個基于主鍵的索引,數(shù)據(jù)庫可以快速通過索引確定表中的行數(shù),而無需讀取表中的每一行數(shù)據(jù)。
實戰(zhàn)分析
話不多說,下面我們通過實驗來驗證上述理論:
第一步:創(chuàng)建表與插入數(shù)據(jù)
用 Chat2DB 給我們生成一個創(chuàng)建表的 sql 語句,直接用自然語言描述我們想要的字段名和字段類型即可生成建表語句,也可以生成測試數(shù)據(jù)。
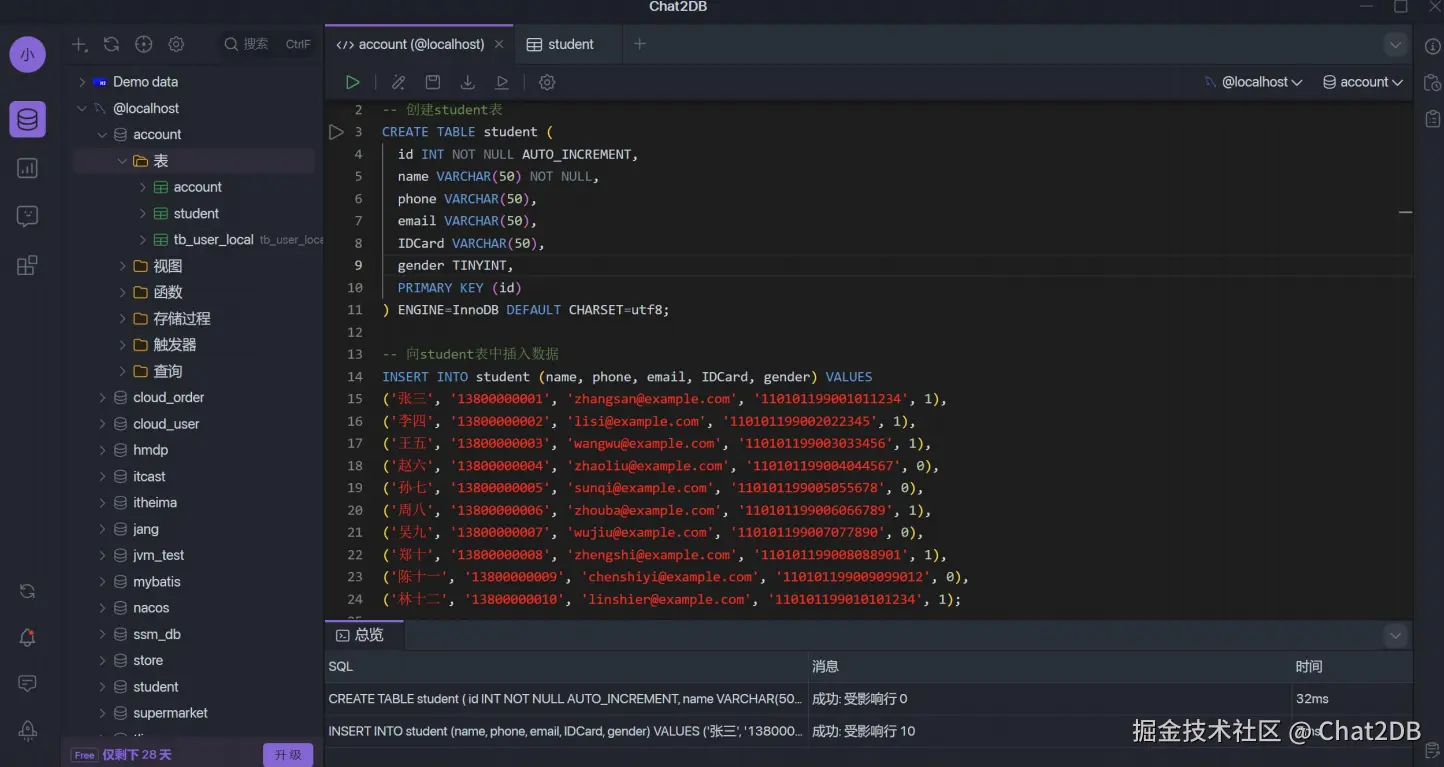
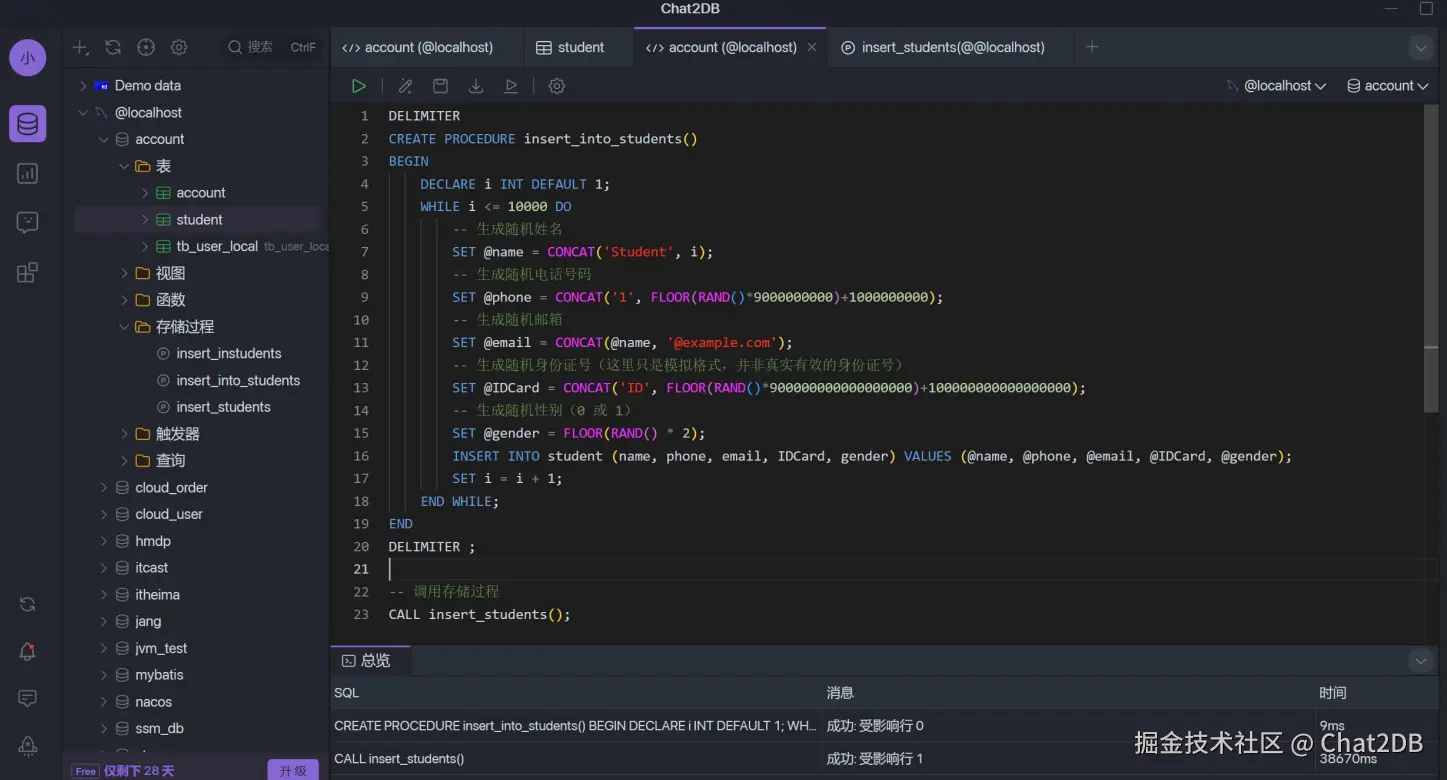
然后用存儲過程向 student 表中插入兩萬條測試數(shù)據(jù)。(存儲過程執(zhí)行兩次)
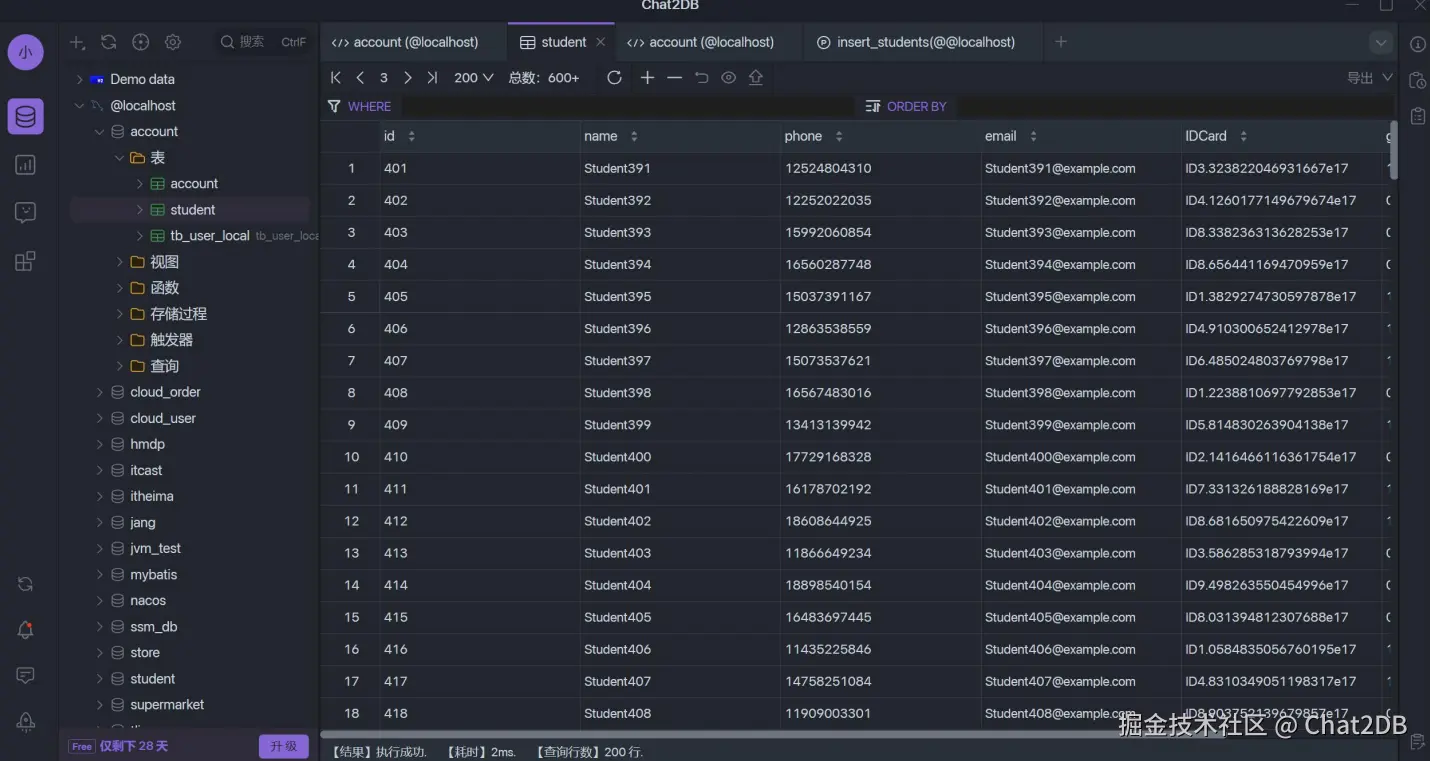
插入數(shù)據(jù)后的 student 表如下:
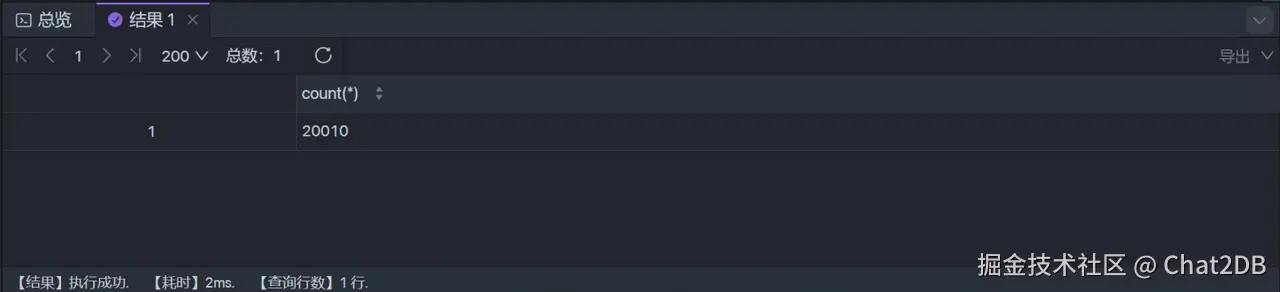
這個時候執(zhí)行 select count(*) from student 和 select count(1) from student 可以看到解釋器的結(jié)果如下,耗時均為 2 ms(兩者一致,所以就只截了一張圖),兩者都用主鍵索引進行行數(shù)的統(tǒng)計:
第二步:執(zhí)行計數(shù)查詢
創(chuàng)建二級索引 IDCard 進行統(tǒng)計結(jié)果如下:

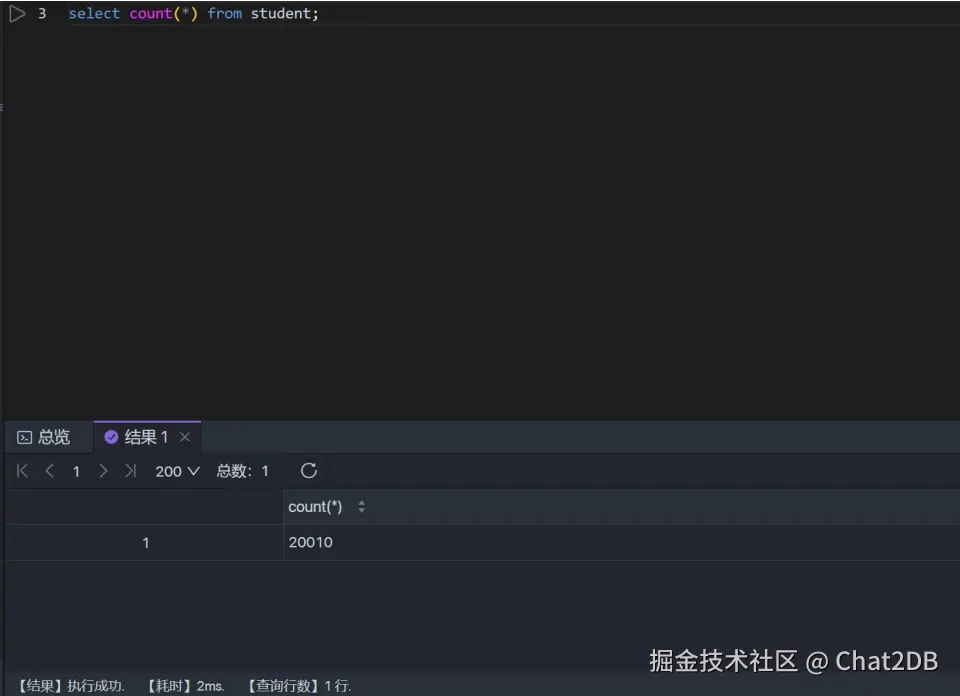
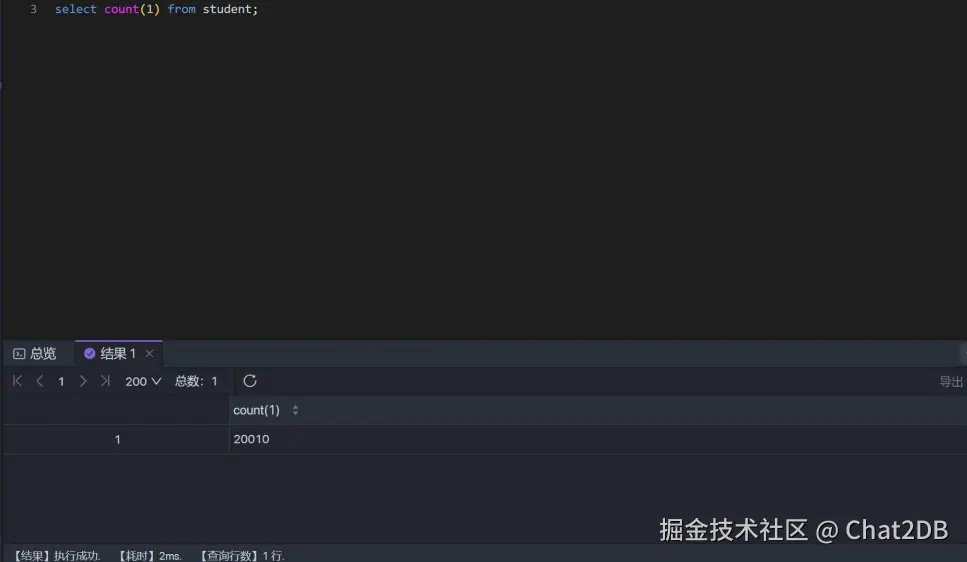
可以看出用二級索引進行統(tǒng)計的解釋器結(jié)果還是一致。
結(jié)論
綜上所述,count(1) 和 count(*) 的性能基本相同,并不存在 COUNT(1) 比 COUNT(*) 更快的說法。總體而言,在大多數(shù)情況下,兩者之間的性能差異是可以忽略不計的。
在選擇使用哪種方式時,應(yīng)當(dāng)優(yōu)先考慮代碼的可讀性和可維護性。count(*) 在語義上更為明確,表示計算所有行的數(shù)量,而不依賴于任何特定的值。因此,從代碼清晰度的角度出發(fā),通常建議優(yōu)先使用 count(*)。
當(dāng)然,如果在特定的數(shù)據(jù)庫環(huán)境中,經(jīng)過實際測試發(fā)現(xiàn) count(1) 具有明顯的性能優(yōu)勢,那么也可以選擇使用 count(1)。但在一般情況下,不必過分糾結(jié)于這兩種計數(shù)方式之間的性能差異。
希望本文能幫助你在使用計數(shù)操作時作出更為合理的選擇。
 :count(1) 和 count(*)哪個性能更好?
:count(1) 和 count(*)哪個性能更好?
的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國內(nèi)大量中小企業(yè)的青睞。")
主要針對港口碼頭集裝箱與散貨日常運作、調(diào)度、堆場、車隊、財務(wù)費用、相關(guān)報表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點,圍繞調(diào)度、堆場作業(yè)而開發(fā)的。集技術(shù)的先進性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
提供了貨物產(chǎn)品管理,銷售管理,采購管理,倉儲管理,倉庫管理,保質(zhì)期管理,貨位管理,庫位管理,生產(chǎn)管理,WMS管理系統(tǒng),標簽打印,條形碼,二維碼管理,批號管理軟件。")
都免費,不限功能、不限時間、不限用戶的免費OA協(xié)同辦公管理系統(tǒng)。")


 400 186 1886
400 186 1886
")

