教程名稱:使用 C# 入門深度學(xué)習(xí)
作者:癡者工良
教程地址:https://torch.whuanle.cn
電子書倉(cāng)庫(kù):https://github.com/whuanle/cs_pytorch
Maomi.Torch 項(xiàng)目倉(cāng)庫(kù):https://github.com/whuanle/Maomi.Torch
開始使用 Torch
本章內(nèi)容主要基于 Pytorch 官方入門教程編寫,使用 C# 代碼代替 Python,主要內(nèi)容包括處理數(shù)據(jù)、創(chuàng)建模型、優(yōu)化模型參數(shù)、保存模型、加載模型,讀者通過(guò)本章內(nèi)容開始了解 TorchSharp 框架的使用方法。
官方教程:
https://pytorch.org/tutorials/beginner/basics/quickstart_tutorial.html
準(zhǔn)備
創(chuàng)建一個(gè)控制臺(tái)項(xiàng)目,示例代碼參考 example2.2,通過(guò) nuget 引入以下類庫(kù):
TorchSharp
TorchSharp-cuda-windows
TorchVision
Maomi.Torch
首先添加以下代碼,查找最適合當(dāng)前設(shè)備的工作方式,主要是選擇 GPU 開發(fā)框架,例如 CUDA、MPS,CPU,有 GPU 就用 GPU,沒有 GPU 降級(jí)為 CPU。
using Maomi.Torch;
Device defaultDevice = MM.GetOpTimalDevice();
torch.set_default_device(defaultDevice);
Console.WriteLine("當(dāng)前正在使用 {defaultDevice}");
下載數(shù)據(jù)集
訓(xùn)練模型最重要的一步是準(zhǔn)備數(shù)據(jù),但是準(zhǔn)備數(shù)據(jù)集是一個(gè)非常繁雜和耗時(shí)間的事情,對(duì)于初學(xué)者來(lái)說(shuō)也不現(xiàn)實(shí),所以 Pytorch 官方在框架集成了一些常見的數(shù)據(jù)集,開發(fā)者可以直接通過(guò) API 使用這些提前處理好的數(shù)據(jù)集和標(biāo)簽。
Pytorch 使用 torch.utils.data.Dataset 表示數(shù)據(jù)集抽象接口,存儲(chǔ)了數(shù)據(jù)集的樣本和對(duì)應(yīng)標(biāo)簽;torch.utils.data.DataLoader 表示加載數(shù)據(jù)集的抽象接口,主要是提供了迭代器。這兩套接口是非常重要的,對(duì)于開發(fā)者自定義的數(shù)據(jù)集,需要實(shí)現(xiàn)這兩套接口,自定義加載數(shù)據(jù)集方式。
Pytorch 有三大領(lǐng)域的類庫(kù),分別是 TorchText、TorchVision、TorchAudio,這三個(gè)庫(kù)都自帶了一些常用開源數(shù)據(jù)集,但是 .NET 里社區(qū)倉(cāng)庫(kù)只提供了 TorchVision,生態(tài)嚴(yán)重落后于 Pytorch。TorchVision 是一個(gè)工具集,可以從 Fashion-MNIST 等下載數(shù)據(jù)集以及進(jìn)行一些數(shù)據(jù)類型轉(zhuǎn)換等功能。
在本章中,使用的數(shù)據(jù)集叫 FashionMNIST,Pytorch 還提供了很多數(shù)據(jù)集,感興趣的讀者參考:https://pytorch.org/vision/stable/datasets.html
現(xiàn)在開始講解如何通過(guò) TorchSharp 框架加載 FashionMNIST 數(shù)據(jù)集,首先添加引用:
using TorchSharp;
using static TorchSharp.torch;
using datasets = TorchSharp.torchvision.datasets;
using transforms = TorchSharp.torchvision.transforms;
然后通過(guò)接口加載訓(xùn)練數(shù)據(jù)集和測(cè)試數(shù)據(jù)集:
var training_data = datasets.FashionMNIST(
root: "data",
train: true,
download: true,
target_transform: transforms.ConvertImageDtype(ScalarType.Float32)
);
var test_data = datasets.FashionMNIST(
root: "data",
train: false,
download: true,
target_transform: transforms.ConvertImageDtype(ScalarType.Float32)
);
部分參數(shù)解釋如下:
root 是存放訓(xùn)練/測(cè)試數(shù)據(jù)的路徑。train 指定訓(xùn)練或測(cè)試數(shù)據(jù)集。download=True 如果 root 中沒有數(shù)據(jù),則從互聯(lián)網(wǎng)下載數(shù)據(jù)。transform 和 target_transform 指定特征和標(biāo)簽轉(zhuǎn)換。
注意,與 Python 版本有所差異, Pytorch 官方給出了 ToTensor() 函數(shù)用于將圖像轉(zhuǎn)換為 torch.Tensor 張量類型,但是由于 C# 版本并沒有這個(gè)函數(shù),因此只能手動(dòng)指定一個(gè)轉(zhuǎn)換器。
啟動(dòng)項(xiàng)目,會(huì)自動(dòng)下載數(shù)據(jù)集,接著在程序運(yùn)行目錄下會(huì)自動(dòng)創(chuàng)建一個(gè) data 目錄,里面是數(shù)據(jù)集文件,包括用于訓(xùn)練的數(shù)據(jù)和測(cè)試的數(shù)據(jù)集。
文件內(nèi)容如下所示,子目錄 test_data 里面的是測(cè)試數(shù)據(jù)集,用于檢查模型訓(xùn)練情況和優(yōu)化。
│ t10k-images-idx3-ubyte.gz
│ t10k-labels-idx1-ubyte.gz
│ train-images-idx3-ubyte.gz
│ train-labels-idx1-ubyte.gz
│
└───test_data
t10k-images-idx3-ubyte
t10k-labels-idx1-ubyte
train-images-idx3-ubyte
train-labels-idx1-ubyte
顯示圖片
數(shù)據(jù)集是 Dataset 類型,繼承了 Dataset<Dictionary<string, Tensor>> 類型,Dataset 本質(zhì)是列表,我們把 Dataset 列表的 item 稱為數(shù)據(jù),每個(gè) item 都是一個(gè)字典類型,每個(gè)字典由 data、label 兩個(gè) key 組成。
在上一節(jié),已經(jīng)編寫好如何加載數(shù)據(jù)集,將訓(xùn)練數(shù)據(jù)和測(cè)試數(shù)據(jù)分開加載,為了了解 Dataset ,讀者可以通過(guò)以下代碼將數(shù)據(jù)集的結(jié)構(gòu)打印到控制臺(tái)。
for (int i = 0; i < training_data.Count; i++)
{
var dic = training_data.GetTensor(i);
var img = dic["data"];
var label = dic["label"];
label.print();
}
通過(guò)觀察控制臺(tái),可以知道,每個(gè)數(shù)據(jù)元素都是一個(gè)字典,每個(gè)字典由 data、label 兩個(gè) key 組成,dic["data"] 是一個(gè)圖片,而 label 就是表示該圖片的文本值是什么。
Maomi.Torch 框架提供了將張量轉(zhuǎn)換為圖片并顯示的方法,例如下面在窗口顯示數(shù)據(jù)集前面的三張圖片:
for (int i = 0; i < training_data.Count; i++)
{
var dic = training_data.GetTensor(i);
var img = dic["data"];
var label = dic["label"];
if (i > 2)
{
break;
}
img.ShowImage();
}
使用 Maomi.ScottPlot.Winforms 庫(kù),還可以通過(guò) img.ShowImageToForm() 接口通過(guò)窗口的形式顯示圖片。
你也可以直接轉(zhuǎn)存為圖片:
img.SavePng("data/{i}.png");
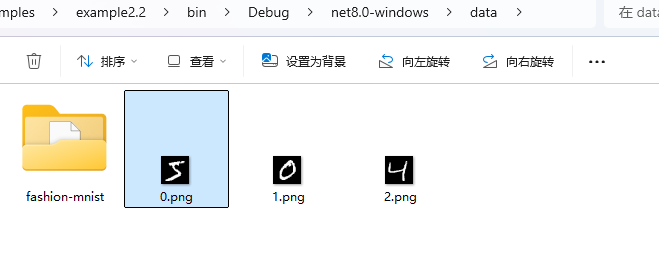
加載數(shù)據(jù)集
由于 FashionMNIST 數(shù)據(jù)集有 6 萬(wàn)張圖片,一次性加載所有圖片比較消耗內(nèi)存,并且一次性訓(xùn)練對(duì) GPU 的要求也很高,因此我們需要分批處理數(shù)據(jù)集。
torch.utils.data 中有數(shù)據(jù)加載器,可以幫助我們分批加載圖片集到內(nèi)存中,開發(fā)時(shí)使用迭代器直接讀取,不需要關(guān)注分批情況。
如下面所示,分批加載數(shù)據(jù)集,批處理大小是 64 張圖片。
var train_loader = torch.utils.data.DataLoader(training_data, batchSize: 64, shuffle: true, device: defaultDevice);
var test_loader = torch.utils.data.DataLoader(test_data, batchSize: 64, shuffle: false, device: defaultDevice);
注意,分批是在 DataLoader 內(nèi)部發(fā)生的,我們可以理解為緩沖區(qū)大小,對(duì)于開發(fā)者來(lái)說(shuō),并不需要關(guān)注分批情況。
定義網(wǎng)絡(luò)
接下來(lái)定義一個(gè)神經(jīng)網(wǎng)絡(luò),神經(jīng)網(wǎng)絡(luò)有多個(gè)層,通過(guò)神經(jīng)網(wǎng)絡(luò)來(lái)訓(xùn)練數(shù)據(jù),通過(guò)數(shù)據(jù)的訓(xùn)練可以的出參數(shù)、權(quán)重等信息,這些信息會(huì)被保存到模型中,加載模型時(shí),必須要有對(duì)應(yīng)的網(wǎng)絡(luò)結(jié)構(gòu),比如神經(jīng)網(wǎng)絡(luò)的層數(shù)要相同、每層的結(jié)構(gòu)一致。
該網(wǎng)絡(luò)通過(guò)接受 28*28 大小的圖片,經(jīng)過(guò)處理后輸出 10 個(gè)分類值,每個(gè)分類結(jié)果都帶有其可能的概率,概率最高的就是識(shí)別結(jié)果。
將以下代碼存儲(chǔ)到 NeuralNetwork.cs 中。
using TorchSharp.Modules;
using static TorchSharp.torch;
using nn = TorchSharp.torch.nn;
public class NeuralNetwork : nn.Module<Tensor, Tensor>
{
public NeuralNetwork() : base(nameof(NeuralNetwork))
{
flatten = nn.Flatten();
linear_relu_stack = nn.Sequential(
nn.Linear(28 * 28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10));
RegisterComponents();
}
Flatten flatten;
Sequential linear_relu_stack;
public override Tensor forward(Tensor input)
{
var x = flatten.call(input);
var logits = linear_relu_stack.call(x);
return logits;
}
}
注意,網(wǎng)絡(luò)中只能定義字段,不要定義屬性;不要使用 _ 開頭定義字段;
然后繼續(xù)在 Program 里繼續(xù)編寫代碼,初始化神經(jīng)網(wǎng)絡(luò),并使用 GPU 來(lái)加載網(wǎng)絡(luò)。
var model = new NeuralNetwork();
model.to(defaultDevice);
優(yōu)化模型參數(shù)
為了訓(xùn)練模型,需要定義一個(gè)損失函數(shù)和一個(gè)優(yōu)化器,損失函數(shù)的主要作用是衡量模型的預(yù)測(cè)結(jié)果與真實(shí)標(biāo)簽之間的差異,即誤差或損失,有了損失函數(shù)后,通過(guò)優(yōu)化器可以指導(dǎo)模型參數(shù)的調(diào)整,使預(yù)測(cè)結(jié)果能夠逐步靠近真實(shí)值,從而提高模型的性能。Pytorch 自帶很多損失函數(shù),這里使用計(jì)算交叉熵?fù)p失的損失函數(shù)。
var loss_fn = nn.CrossEntropyLoss();
var optimizer = torch.optim.SGD(model.parameters(), learningRate : 1e-3);
同時(shí),優(yōu)化器也很重要,是用于調(diào)整模型參數(shù)以最小化損失函數(shù)的模塊。
因?yàn)閾p失函數(shù)比較多,但是優(yōu)化器就那么幾個(gè),所以這里簡(jiǎn)單列一下 Pytorch 中自帶的一些優(yōu)化器。
- SGD(隨機(jī)梯度下降):通過(guò)按照損失函數(shù)的梯度進(jìn)行線性步長(zhǎng)更新權(quán)重;
- Adam(自適應(yīng)矩估計(jì)) :基于一階和二階矩估計(jì)的優(yōu)化算法,它能自適應(yīng)地調(diào)整學(xué)習(xí)率,對(duì)大多數(shù)問題效果較好;
- RMSprop:適用于處理非平穩(wěn)目標(biāo),能夠自動(dòng)進(jìn)行學(xué)習(xí)率的調(diào)整;
- AdamW(帶權(quán)重衰減的 Adam) :在 Adam 的基礎(chǔ)上添加了權(quán)重衰減(weight decay),防止過(guò)擬合。
訓(xùn)練模型
接下來(lái)講解訓(xùn)練模型的步驟,如下代碼所示。
下面是詳細(xì)步驟:
- 每讀取一張圖片,就使用神經(jīng)網(wǎng)絡(luò)進(jìn)行識(shí)別(
.call() 函數(shù)),pred 為識(shí)別結(jié)果; - 通過(guò)損失函數(shù)判斷網(wǎng)絡(luò)的識(shí)別結(jié)果和標(biāo)簽值的誤差;
- 通過(guò)損失函數(shù)反向傳播,計(jì)算網(wǎng)絡(luò)的梯度等;
- 通過(guò) SGD 優(yōu)化器,按照損失函數(shù)的梯度進(jìn)行線性步長(zhǎng)更新權(quán)重,
optimizer.step() 會(huì)調(diào)整模型的權(quán)重,根據(jù)計(jì)算出來(lái)的梯度來(lái)更新模型的參數(shù),使模型逐步接近優(yōu)化目標(biāo)。 - 因?yàn)閿?shù)據(jù)是分批處理的,因此計(jì)算當(dāng)前批次的梯度后,需要使用
optimizer.zero_grad() 重置當(dāng)前所有梯度。 - 計(jì)算訓(xùn)練成果,即打印當(dāng)前訓(xùn)練進(jìn)度和損失值。
static void Train(DataLoader dataloader, NeuralNetwork model, CrossEntropyLoss loss_fn, SGD optimizer)
{
var size = dataloader.dataset.Count;
model.train();
int batch = 0;
foreach (var item in dataloader)
{
var x = item["data"];
var y = item["label"];
var pred = model.call(x);
var loss = loss_fn.call(pred, y);
loss.backward();
optimizer.step();
optimizer.zero_grad();
if (batch % 100 == 0)
{
loss = loss.item<float>();
var current = (batch + 1) * x.shape[0];
Console.WriteLine("loss: {loss.item<float>(),7} [{current,5}/{size,5}]");
}
batch++;
}
}
torch.Tensor 類型的 .shape 屬性比較特殊,是一個(gè)數(shù)組類型,主要用于存儲(chǔ)當(dāng)前類型的結(jié)構(gòu),要結(jié)合上下文才能判斷,例如在當(dāng)前訓(xùn)練中,x.shape 值是 [64,1,28,28],shape[1] 是圖像的通道,1 是灰色,3 是彩色(RGB三通道);shape[2]、shape[3] 分別是圖像的長(zhǎng)度和高度。
通過(guò)上面步驟可以看出,“訓(xùn)練” 是一個(gè)字面意思,跟人類的學(xué)習(xí)不一樣,這里是先使用模型識(shí)別一個(gè)圖片,然后計(jì)算誤差,更新模型參數(shù)和權(quán)重,然后進(jìn)入下一次調(diào)整。
訓(xùn)練模型的同時(shí),我們還需要評(píng)估模型的準(zhǔn)確率等信息,評(píng)估時(shí)需要使用測(cè)試圖片來(lái)驗(yàn)證訓(xùn)練結(jié)果。
static void Test(DataLoader dataloader, NeuralNetwork model, CrossEntropyLoss loss_fn)
{
var size = (int)dataloader.dataset.Count;
var num_batches = (int)dataloader.Count;
model.eval();
var test_loss = 0F;
var correct = 0F;
using (var n = torch.no_grad())
{
foreach (var item in dataloader)
{
var x = item["data"];
var y = item["label"];
var pred = model.call(x);
test_loss += loss_fn.call(pred, y).item<float>();
correct += (pred.argmax(1) == y).type(ScalarType.Float32).sum().item<float>();
}
}
test_loss /= num_batches;
correct /= size;
Console.WriteLine("Test Error: \n Accuracy: {(100 * correct):F1}%, Avg loss: {test_loss:F8} \n");
}
下圖是后面訓(xùn)練打印的日志,可以看出準(zhǔn)確率是逐步上升的。
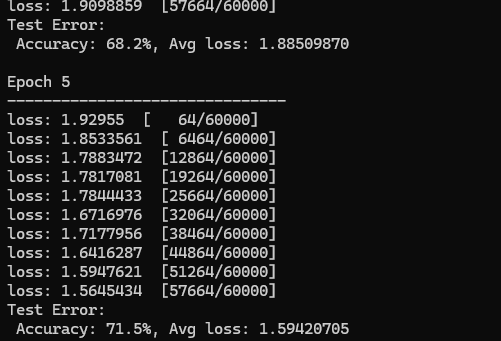
在 Program 中添加訓(xùn)練代碼,我們使用訓(xùn)練數(shù)據(jù)集進(jìn)行五輪訓(xùn)練,每輪訓(xùn)練都輸出識(shí)別結(jié)果。
var epochs = 5;
foreach (var epoch in Enumerable.Range(0, epochs))
{
Console.WriteLine("Epoch {epoch + 1}\n-------------------------------");
Train(train_loader, model, loss_fn, optimizer);
Test(train_loader, model, loss_fn);
}
Console.WriteLine("Done!");
保存和加載模型
經(jīng)過(guò)訓(xùn)練后的模型,可以直接保存和加載,代碼很簡(jiǎn)單,如下所示:
model.save("model.dat");
Console.WriteLine("Saved PyTorch Model State to model.dat");
model.load("model.dat");
使用模型識(shí)別圖片
要使用模型識(shí)別圖片,只需要使用 var pred = model.call(x); 即可,但是因?yàn)槟P筒⒉荒苤苯虞敵鲎R(shí)別結(jié)果,而是根據(jù)網(wǎng)絡(luò)結(jié)構(gòu)輸出到每個(gè)神經(jīng)元中,每個(gè)神經(jīng)元都表示當(dāng)前概率。在前面定義的網(wǎng)絡(luò)中,nn.Linear(512, 10)) 會(huì)輸出 10 個(gè)分類結(jié)果,每個(gè)分類結(jié)果都帶有概率,那么我們將概率最高的一個(gè)結(jié)果拿出來(lái),就相當(dāng)于圖片的識(shí)別結(jié)果了。
代碼如下所示,步驟講解如下:
- 因?yàn)槟P秃途W(wǎng)絡(luò)并不使用字符串表示每個(gè)分類結(jié)果,所以需要手動(dòng)配置分類表。
- 然后從測(cè)試數(shù)據(jù)集中選取第一個(gè)圖片和標(biāo)簽,識(shí)別圖片并獲得序號(hào)。
- 從分類字符串中通過(guò)序號(hào)獲得分類名稱。
var classes = new string[] {
"T-shirt/top",
"Trouser",
"Pullover",
"Dress",
"Coat",
"Sandal",
"Shirt",
"Sneaker",
"Bag",
"Ankle boot",
};
model.eval();
var x = test_data.GetTensor(0)["data"];
var y = test_data.GetTensor(0)["label"];
using (torch.no_grad())
{
x = x.to(defaultDevice);
var pred = model.call(x);
var predicted = classes[pred[0].argmax(0).ToInt32()];
var actual = classes[y.ToInt32()];
Console.WriteLine("Predicted: \"{predicted}\", Actual: \"{actual}\"");
}
當(dāng)然,使用 Maomi.Torch 的接口,可以很方便讀取圖片使用模型識(shí)別:
var img = MM.LoadImage("0.png");
using (torch.no_grad())
{
img = img.to(defaultDevice);
var pred = model.call(img);
var array = torch.nn.functional.softmax(pred, dim: 0);
var max = array.ToFloat32Array().Max();
var predicted = classes[pred[0].argmax(0).ToInt32()];
Console.WriteLine("識(shí)別結(jié)果 {predicted},概率 {max * 100}%");
}
晴ERP是一款針對(duì)中小制造業(yè)的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國(guó)內(nèi)大量中小企業(yè)的青睞。")
晴PMS碼頭管理系統(tǒng)主要針對(duì)港口碼頭集裝箱與散貨日常運(yùn)作、調(diào)度、堆場(chǎng)、車隊(duì)、財(cái)務(wù)費(fèi)用、相關(guān)報(bào)表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點(diǎn),圍繞調(diào)度、堆場(chǎng)作業(yè)而開發(fā)的。集技術(shù)的先進(jìn)性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
晴WMS倉(cāng)儲(chǔ)管理系統(tǒng)提供了貨物產(chǎn)品管理,銷售管理,采購(gòu)管理,倉(cāng)儲(chǔ)管理,倉(cāng)庫(kù)管理,保質(zhì)期管理,貨位管理,庫(kù)位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號(hào)管理軟件。")
晴免費(fèi)OA是一款軟件和通用服務(wù)都免費(fèi),不限功能、不限時(shí)間、不限用戶的免費(fèi)OA協(xié)同辦公管理系統(tǒng)。")


 400 186 1886
400 186 1886
晴公司官網(wǎng)")

